> For the complete documentation index, see [llms.txt](https://folko.gitbook.io/podgotovka-k-sobesedovaniyu/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://folko.gitbook.io/podgotovka-k-sobesedovaniyu/brokery-soobshenii/kafka.md).
# kafka

#### Давайте разберемся, что такое Apache Kafka
**Введение в Apache Kafka**
Для тех, кто не поднимал сейчас руку, поясню, что у Kafka много компонентов. Первый из них – это producer. Producer – это тот, кто создает кучу сообщений и отправляет их куда-то.

На другом конце находится consumer. Они употребляют эти данные, что-то с ними делают.
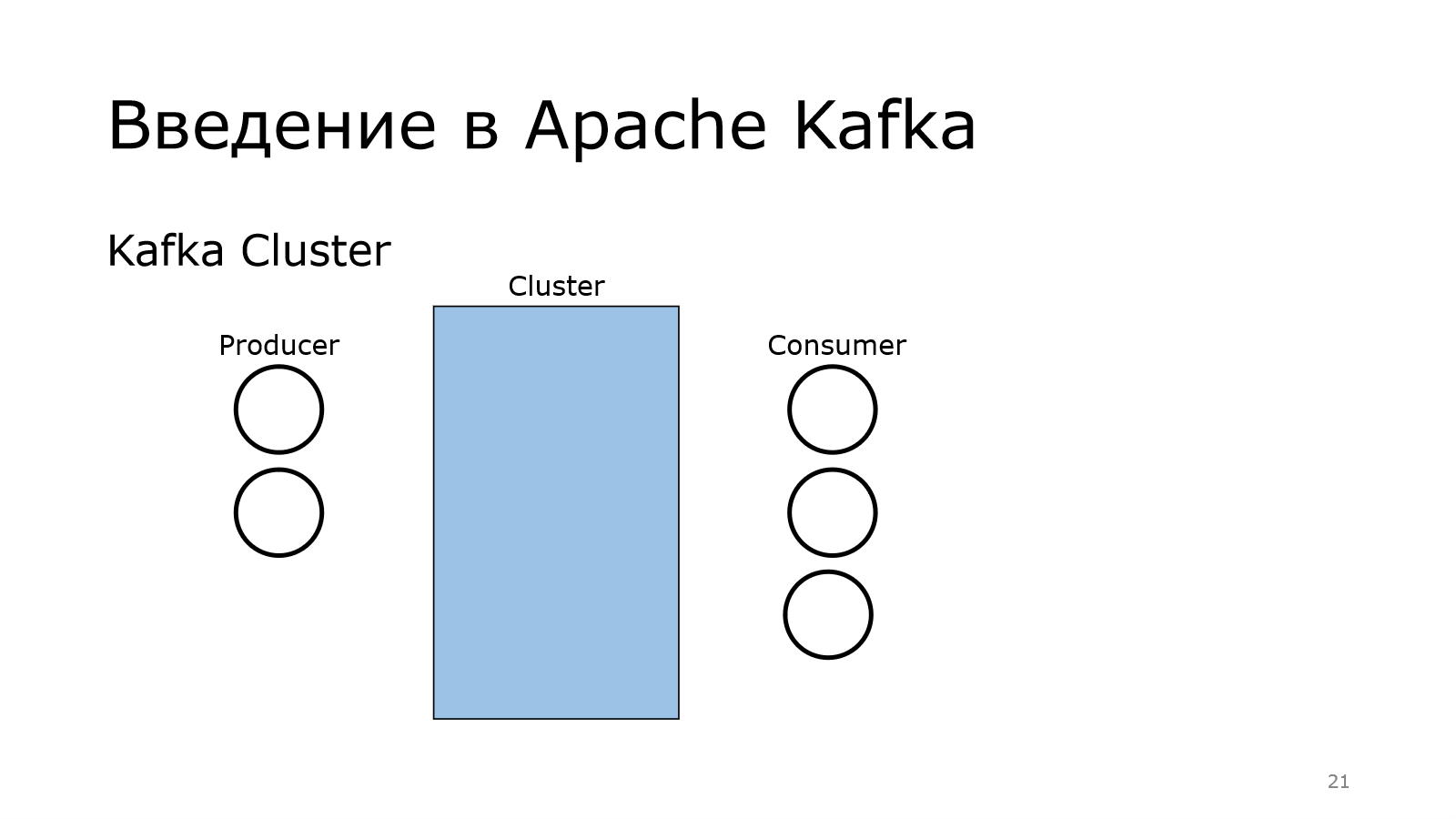
Передача осуществляется через кластер. Там у меня было написано, что Apache Kafka – это распределенный брокер сообщений. Получается, что у нас есть в кластере куча брокеров.
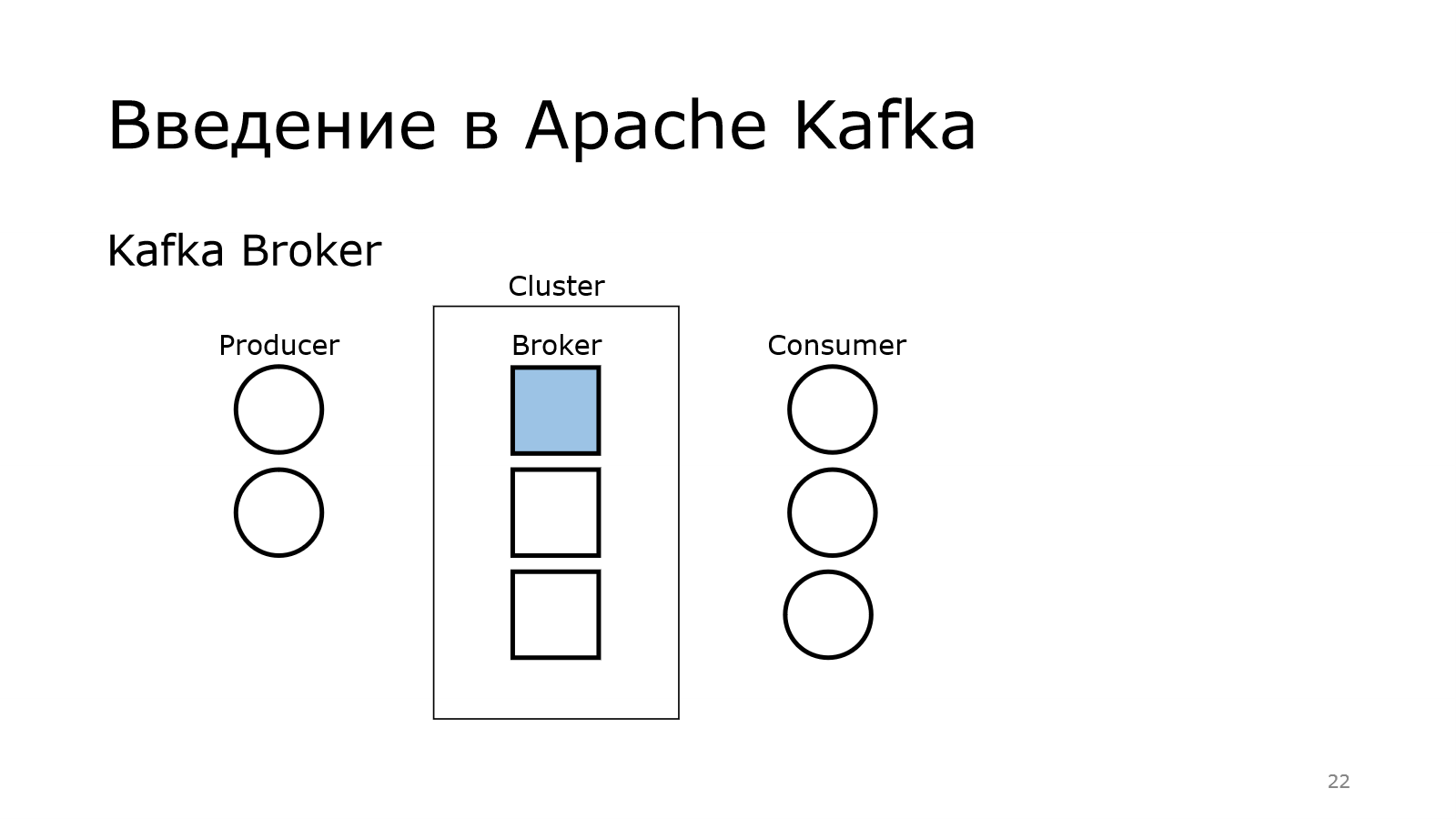
У нас в кластере есть куча брокеров.
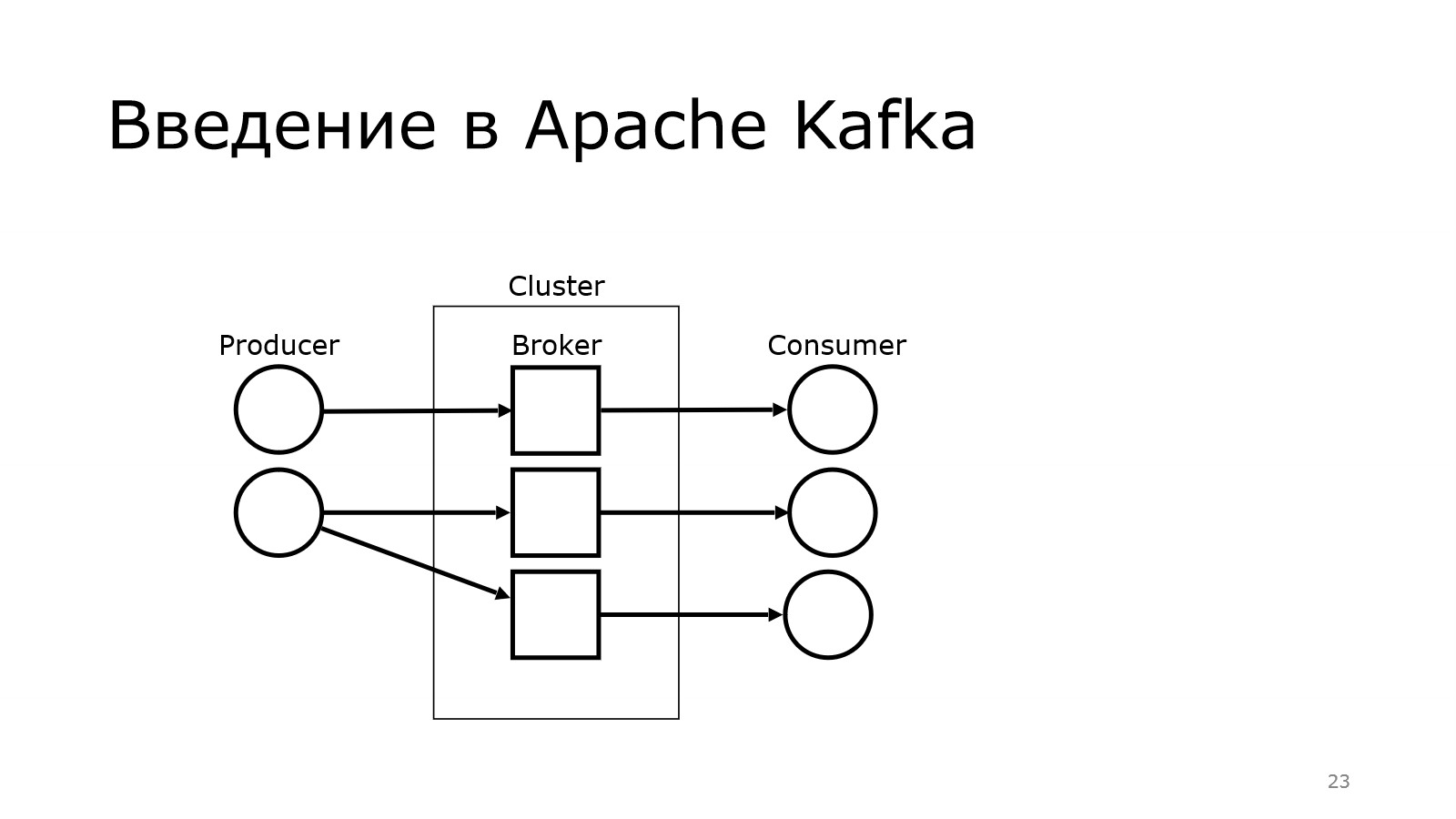
Передача сообщений осуществляется через них.
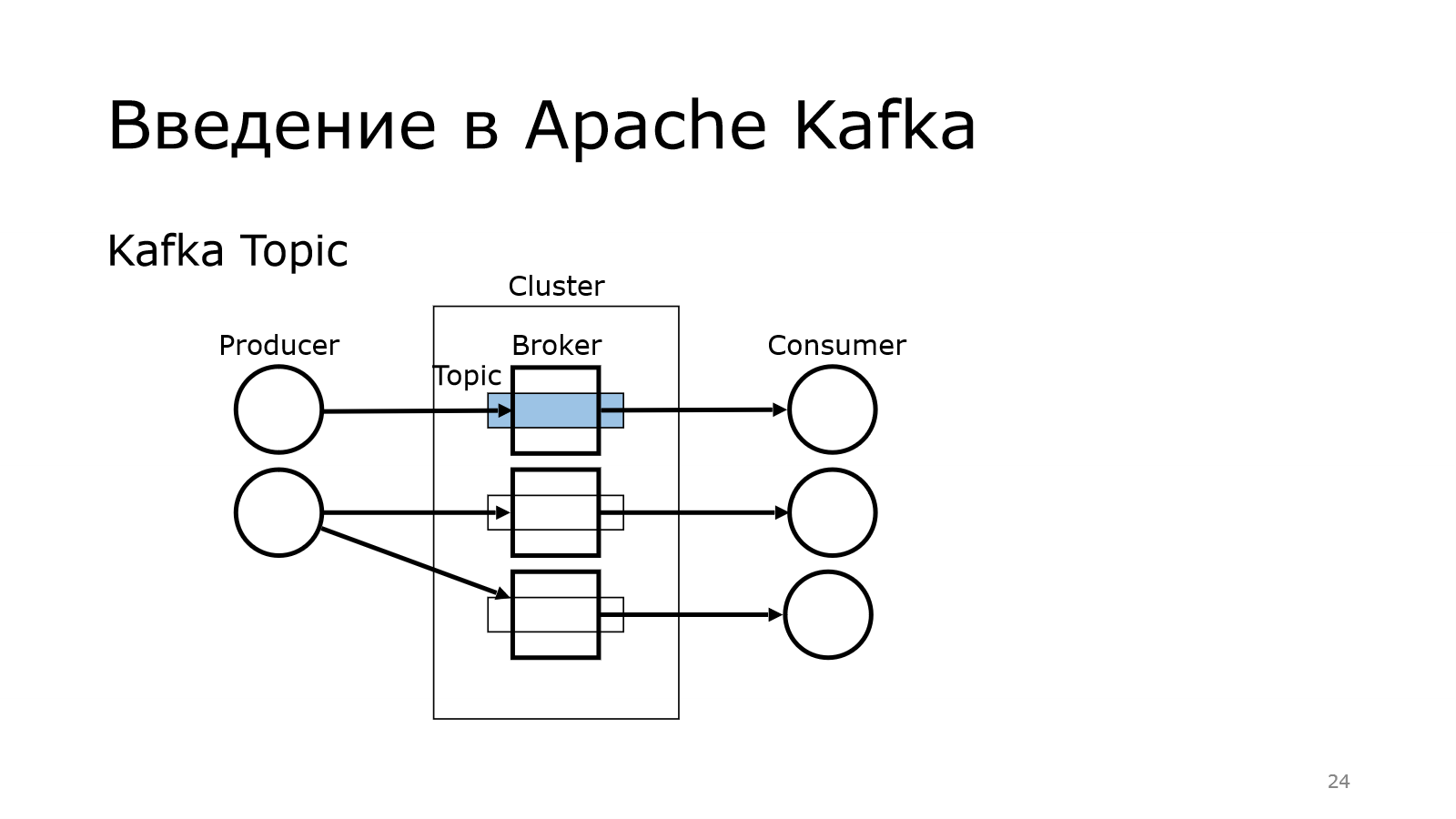
И там брокер выступает таким звеном, который позволяет от producer к consumer не напрямую данные передавать, а через такой топик. Опытный слушатель может сказать, что это обычный Message Queue. Обычный, но не совсем.

Там используется Publish-Subscribe, т. е. у нас просто продюсер пихает сообщение в топик, а consumers могут подписываться на них. И одни и те же сообщения могут читаться разными consumers.
И важно, что для чтения используется poll-механика, т. е. брокер не должен говорить: «Вот, consumer, тебе новое сообщение. Забери его». Каждый consumer должен прийти к Kafka и сказать: «Есть что-то новое?». И она отдает данные.
Такой подход лучше масштабируется, чем, когда сам брокер начинает вливать данные в consumers.
**Архитектура Apache Kafka**
* Topic
* Broker
* Producer
* Consumer
Мы увидели 4 важные вещи. Это топик, брокер, producer и consumer. Давайте по ним и пойдем в таком порядке.
**Архитектура Kafka Topic**

Топик – это логическая единица, которая связывает между собой producers, consumers. И есть какое-то физическое хранение. Каждый такой топик – это множество партиций.
В данном случае у нас топик с тремя партициями. В них записано сообщение. Что при этом важно?

* Сообщения всегда пишутся в конец партиции.

* Писать можно параллельно в несколько партиций одновременно. Они между собой никак не связаны, физически это разные вещи.

При этом у каждого сообщения есть свой номер, свой offset. Каждая партиция начинается с номера 0.
И там они увеличиваются на единичку. Offset = 0

Все вроде бы просто.

Но партиция может стать очень большой. Она может начать весить десятки, сотни гигабайт. А видео одного такого файла не похоронить, поэтому каждая партиция делится на сегменты.
Вот у нас такая длинная-длинная партиция.

Она делится на кусочки.

Они примерно одинакового размера, т. е. 1 сегмент, 2 сегмент и т. д.

И есть последний сегмент.

Последний сегмент еще по-другому называется активным сегментом. Это тот сегмент, в который можно писать данные. Благодаря этому сохраняется правило, что пишем всегда в конец партиции. Это логично.

У нас каждый такой сегмент начинал с некоторого сообщения.
Вот такой базовый offset, с которого начинается каждый из сегментов.

Он состоит из четырех вещей. Про базовый offset уже понятно.

Он используется для того, чтобы называть файлики, которые лежат в файловой системе. И также data, index, timeindex – это три файла.
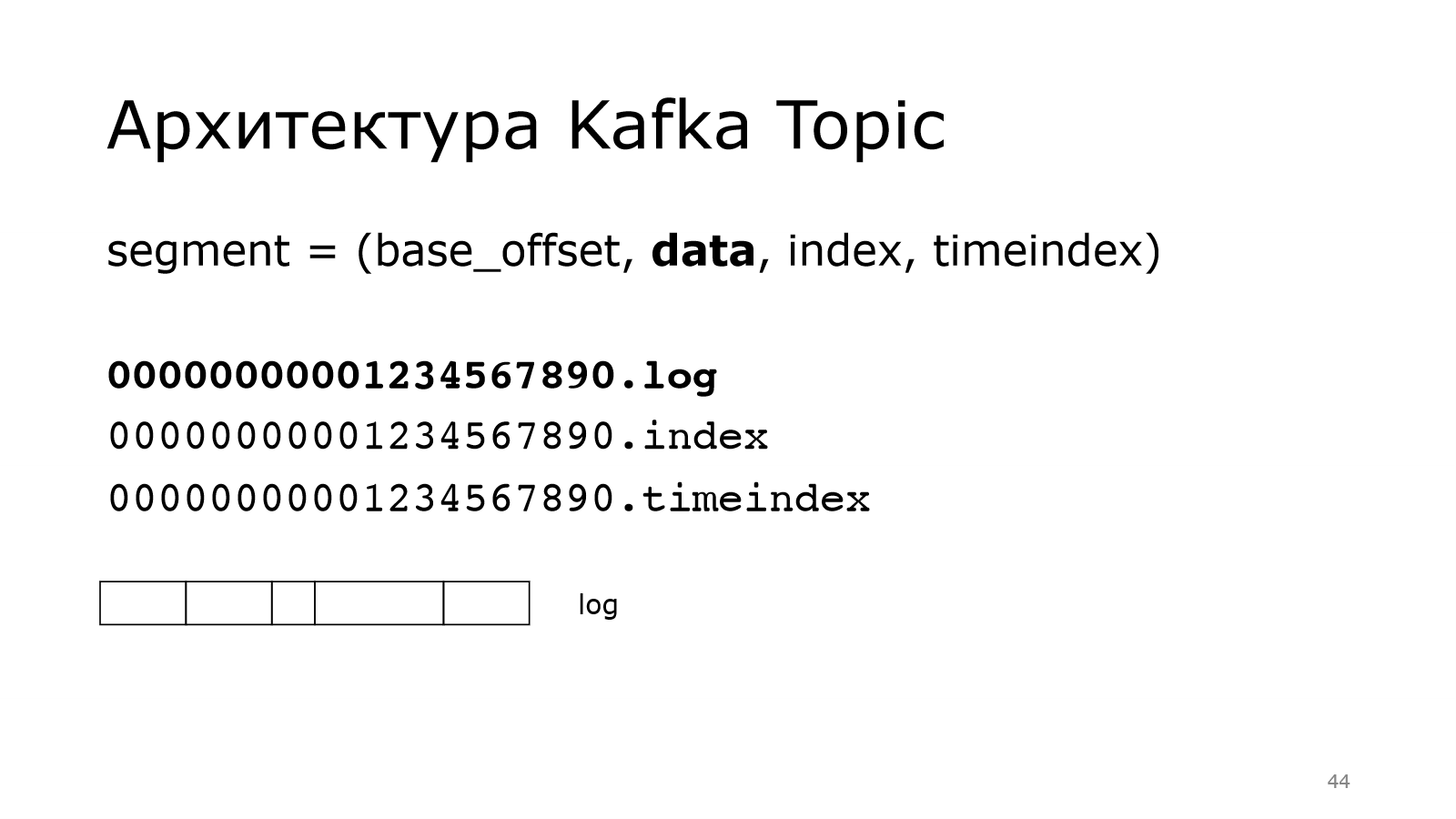
Data – это наши данные, т. е. есть какой-то здоровый файл. И в нем лежат сообщения. Сообщения могут быть разного размера. Kafka все равно, складывайте, что хотите в нее.
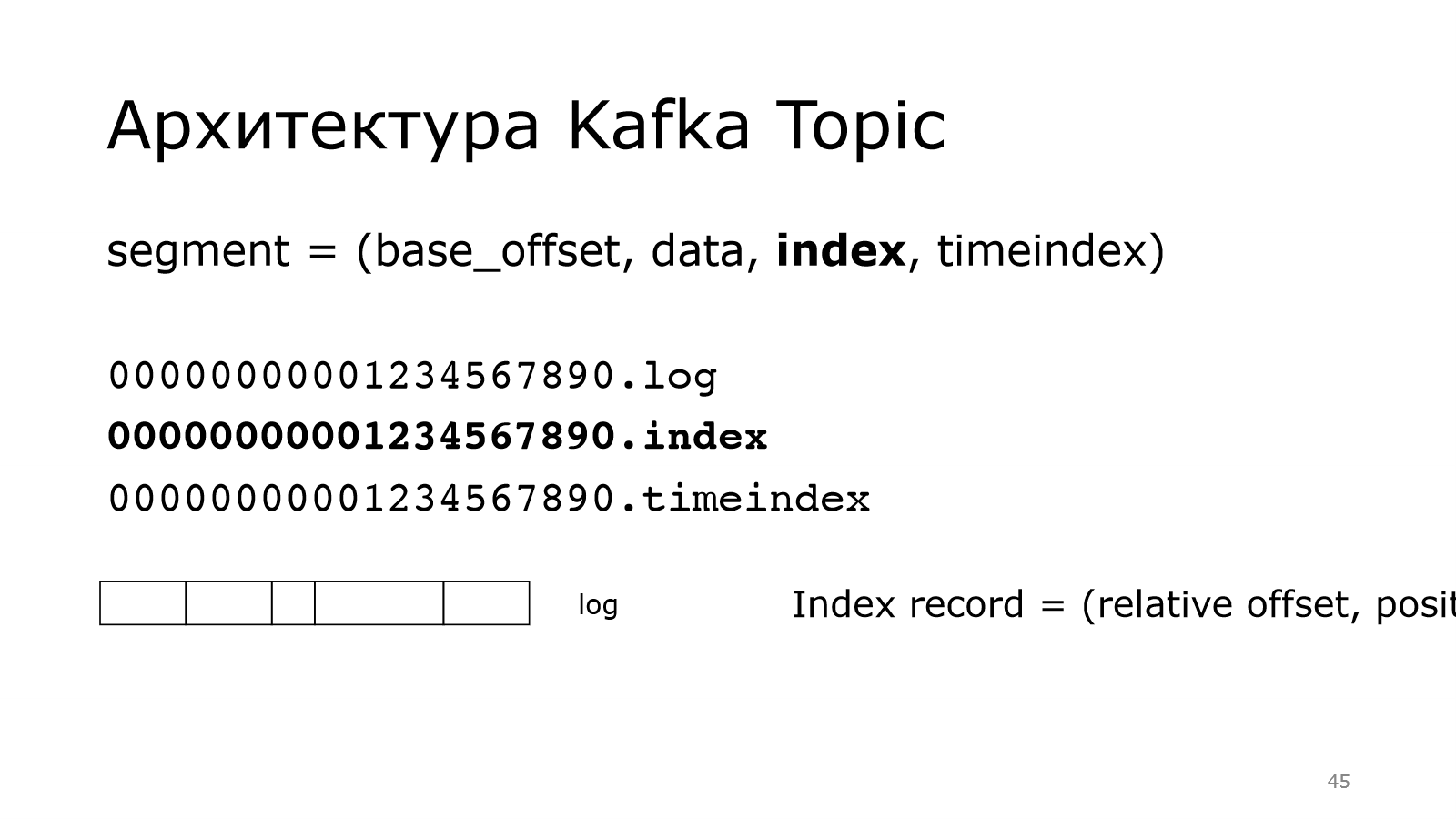
Что такое index? Если мы хотим найти какое-то сообщение по смещению, то надо уметь это делать быстро. Как раз index позволяет это делать.

Он выглядит следующим образом. Каждая запись в index занимает в общей сложности 8 байт. Там два int: relative offset, positon.
Relative offset – это смещение от начала сегмента.
Берем offset сообщения, вычитаем базовый offset, получаем вот это число.
Сообщений в партиции могут быть миллиарды, соответственно базовый offset будет большой и не влезет в int. Но у нас сегмент небольшой, поэтому относительный offset влезет в int.
Тоже самое с position. Position – это просто физическое смещение данного сообщения в этом лог-файле.

Получается, что у нас растет relative offset на единичку, позиция смещается относительно размера предыдущих сообщений.

Он потихоньку растет-растет.

И так можно будет потом искать по этому индексу. Мы знаем номер сообщения, который мы хотим найти. Быстро через базовый offset находим relative offset и в индексе смотрим его позицию, и можно забирать.
Понятно, что там не все сообщения хранятся, а только какие-то выборочные. Там есть шаг, с котором их можно сохранять в индекс. Это все настраивается в Kafka.

Похожим образом устроен timeindex. Для чего он нужен? Каждое сообщение в Kafka имеет какую-то метку времени. И неплохо бы уметь искать по этой ветке времени. Timeindex решает эту задачу.
**Архитектура Kafka Broker**
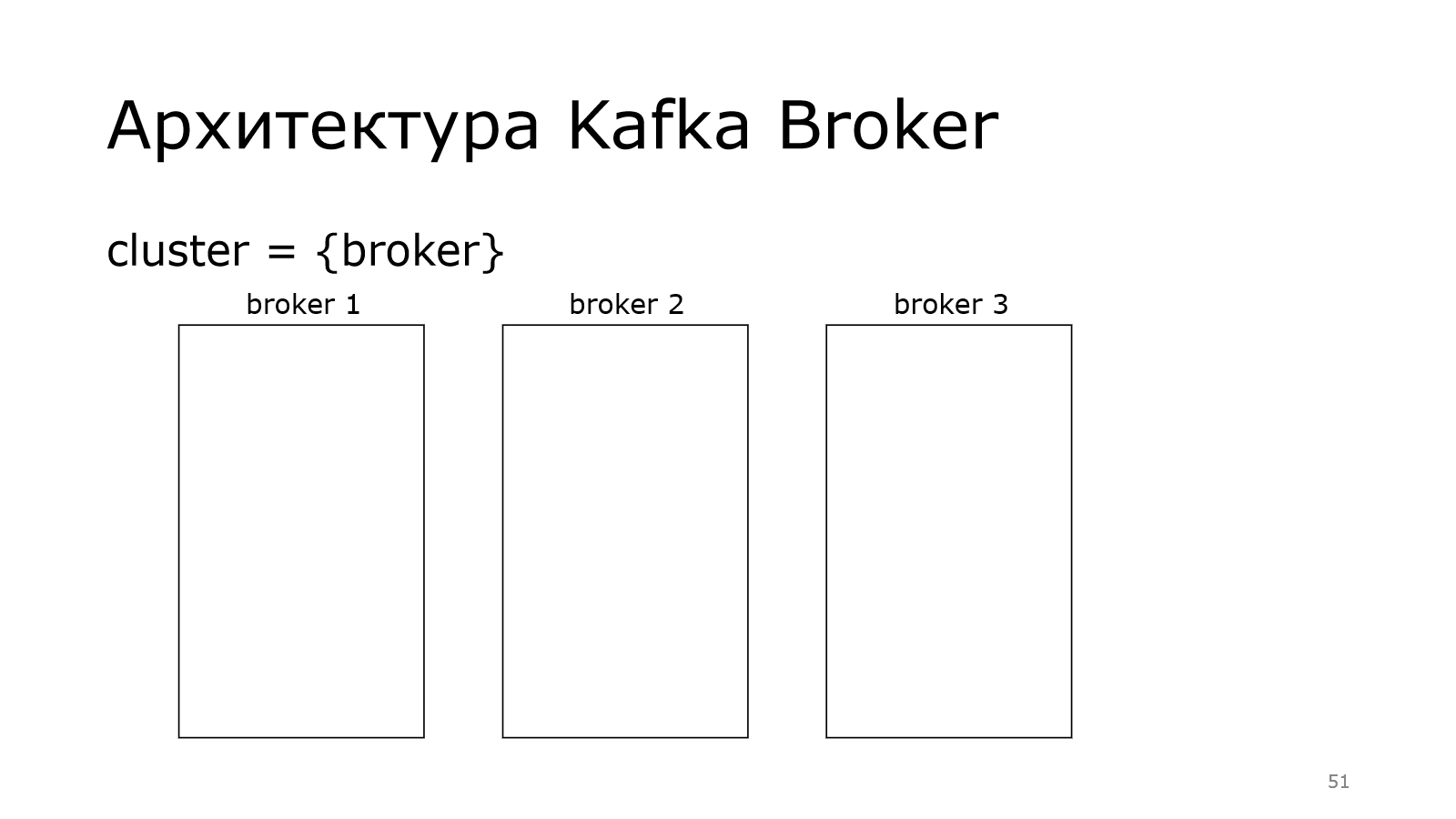
Вернемся к кластеру, к брокерам. Кластер – это множество брокеров.
Один из них отвечает за контроллер.

Он координирует работу кластера. О его назначении мы поговорим чуть попозже.

У нас есть топик, который состоит из нескольких партиций. В данном случае мы создали топик на кластере из трех брокеров. И партиции распределились по кластеру.
При этом Kafka надежная, у нее есть replication factor для каждого топика. И мы можем сказать, что он равен трем.

Это означает, что каждая партиция должна иметь три копии. У нас три копии, поэтому на каждом брокере будет по копии.
Вот у нас 4 партиции на одном, на втором и на третьем.
При этом Kafka позволяет добавлять новые партиции к топику.

Поэтому, если у нас данных станет много, можно увеличить единицу параллелизации.
Партиция – это единица параллелизации, поэтому можно добавить еще одну. И там producers стало больше, которые могут писать с той же эффективностью.
Теперь поговорим о роли контроллера. Дело в том, что контроллер должен назначить лидера. Каждая партиция должна иметь своего лидера.
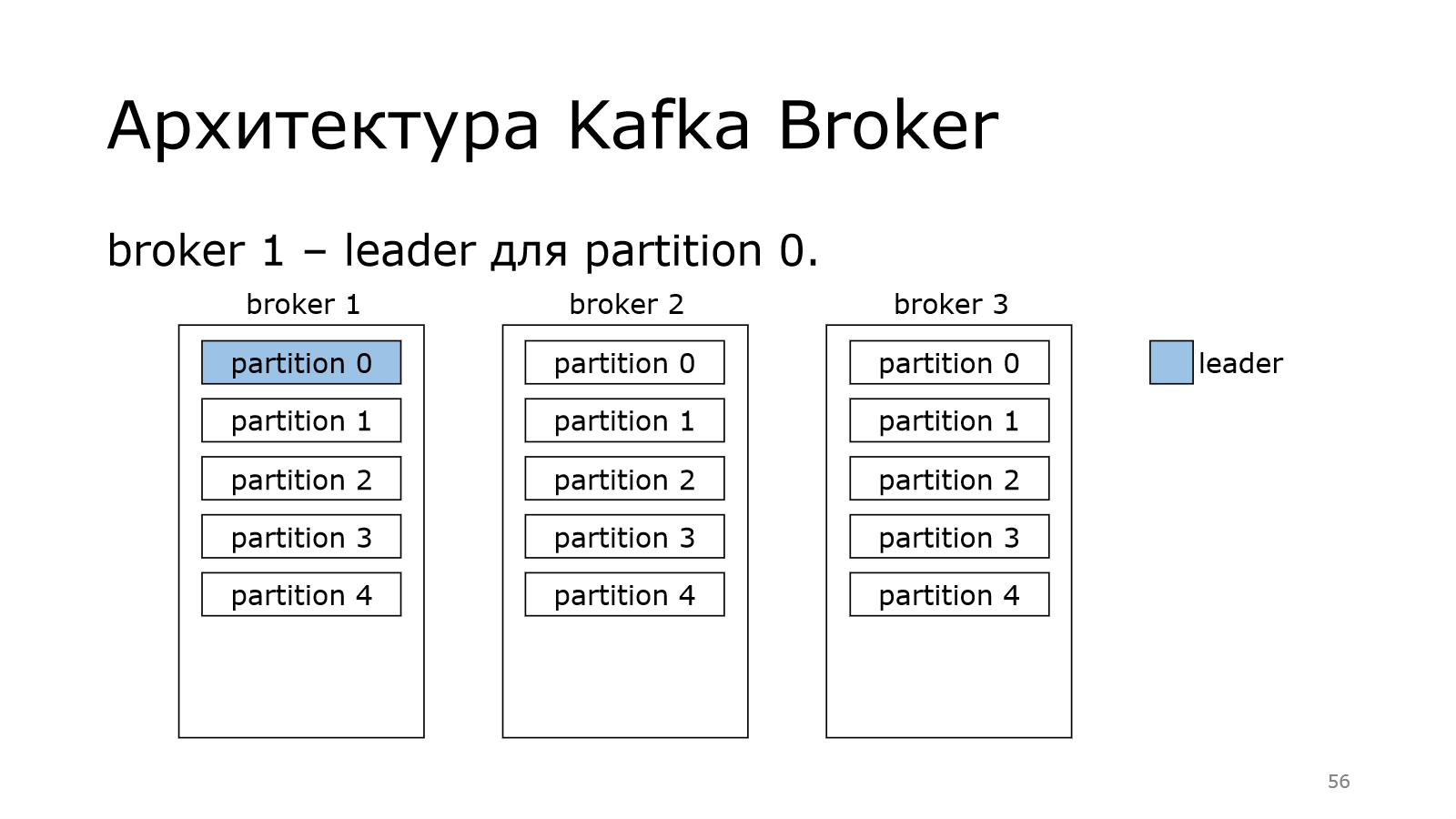
Лидер – это тот брокер, который отвечает за запись в конкретную партицию. Не может быть у одной партиции несколько лидеров. Иначе каждый из них что-то написал бы свое, а потом это никак нельзя было бы соединить в какую-то одну последовательную партицию.

И каждый брокер может стать лидером у некоторых партиций.
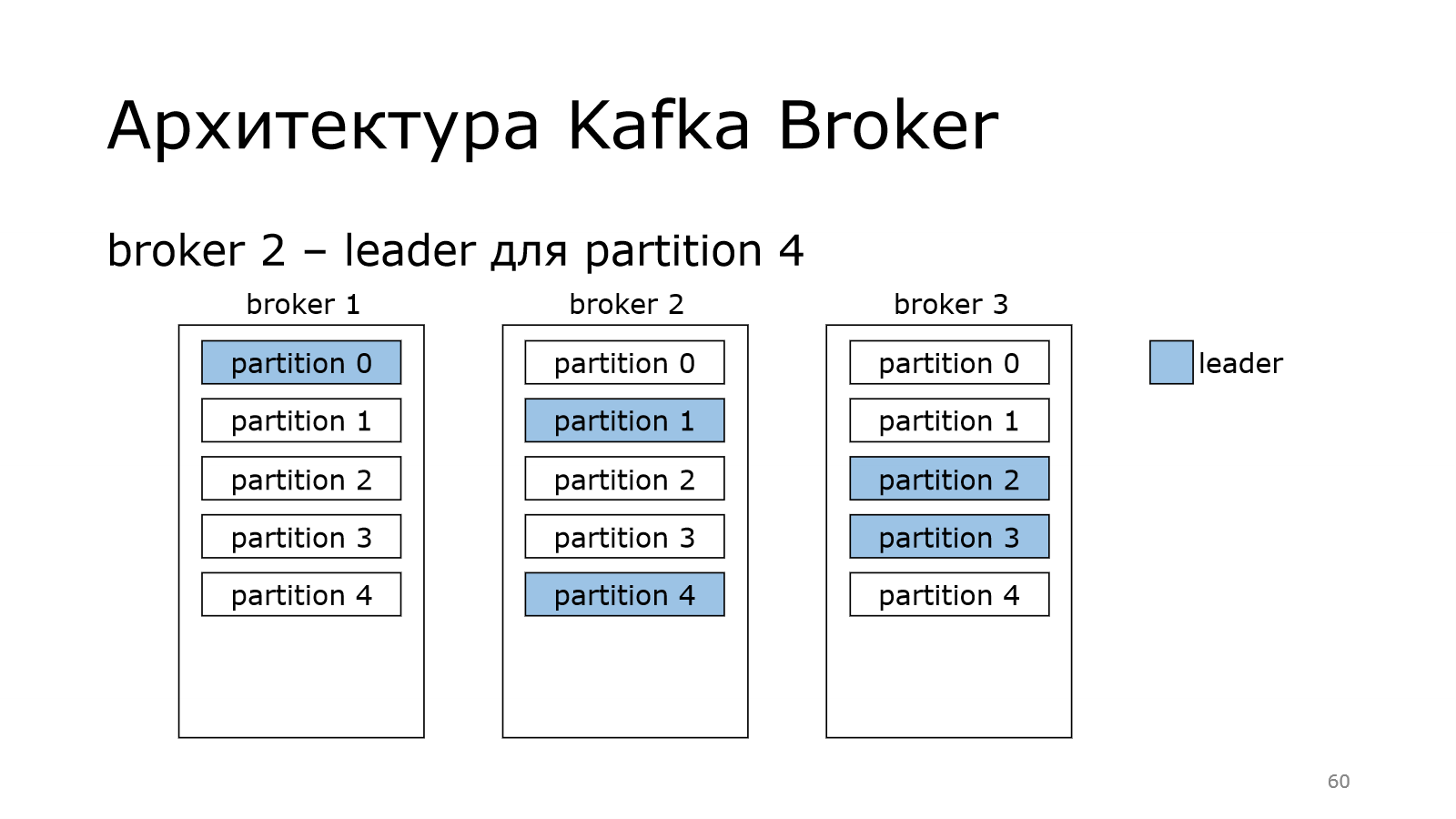
В данном случае получилось так, что у нас на одном брокере лидерство двух партиций. На одном всего одна.
Kafka старается это равномерно распределять по кластеру и балансировать, чтобы не получилось так, что один брокер пыхтит и в себя все пишет-пишет, а остальные отдыхают. Чтобы такого не было, она равномерно пытается распределить.
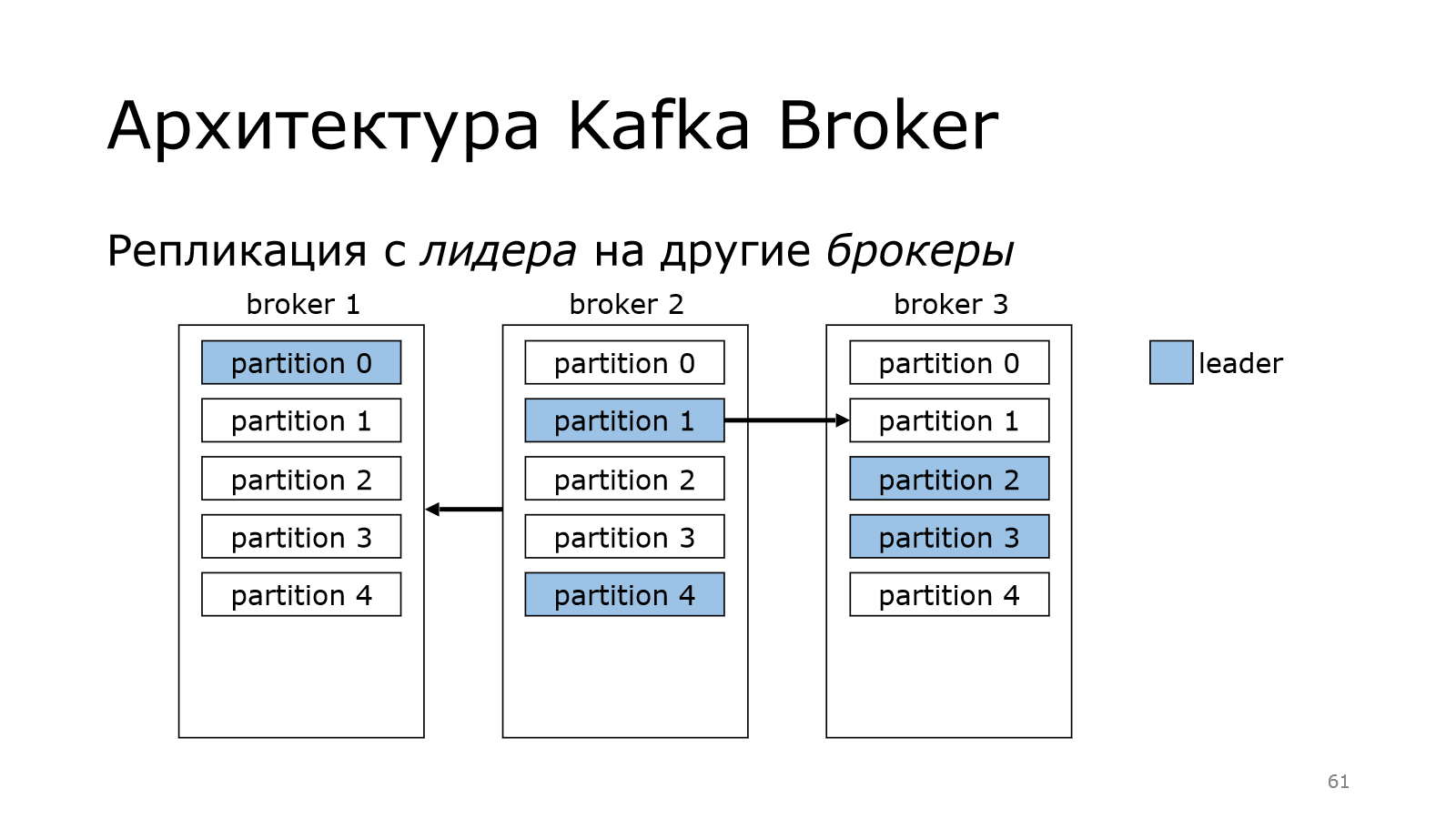
Что происходит дальше? Данные, которые пишутся в лидера, должны быть распределены по репликам. Те, кто в себя тащат данные из лидера, называются follower. Они следуют за ним и потихоньку подкачивают к себе данные.
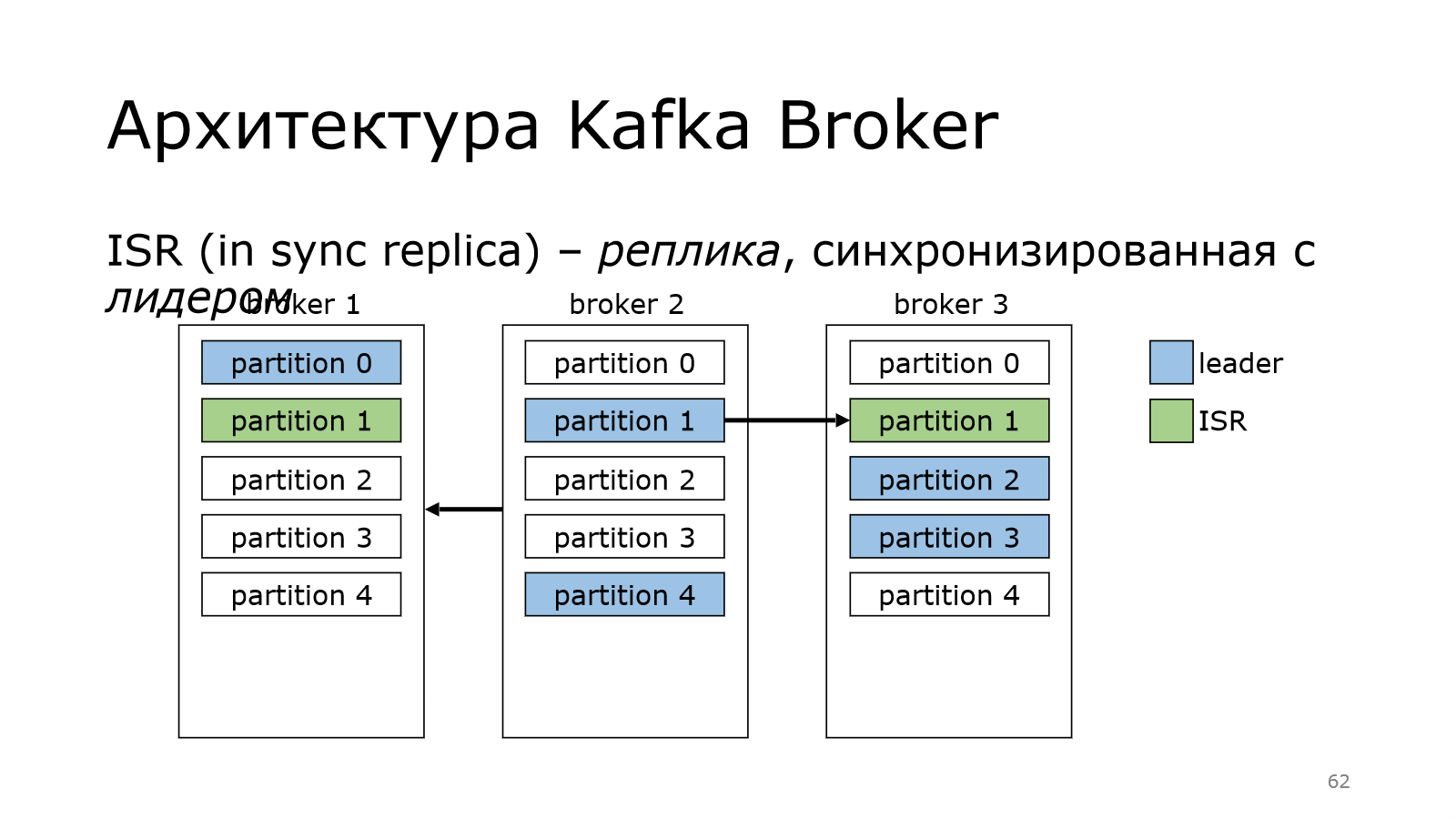
После того, как они сохранили в себе все данные, они становятся крутыми, они становятся in sync replica. Это реплика, которая синхронизирована с лидером.

И в идеале у нас весь кластер должен быть синхронизирован, т. е. все реплики должны быть в списке in sync replica.
Понятно, что какая-то из реплик может выпасть. Если это follower, то ничего страшного? Почему? Потому что follower ходит в лидер за данными. И подумаешь, если один из них перестанет ходить.

А что произойдет, если сам лидер пропадает?
У нас был лидер в брокер 3 на партиции 2, а потом пропал. В этот момент мы данные писать не можем, потому что лидера нет.

Kafka не теряется, она выбирает нового лидера. И за это отвечает контроллер. Все, отлично.
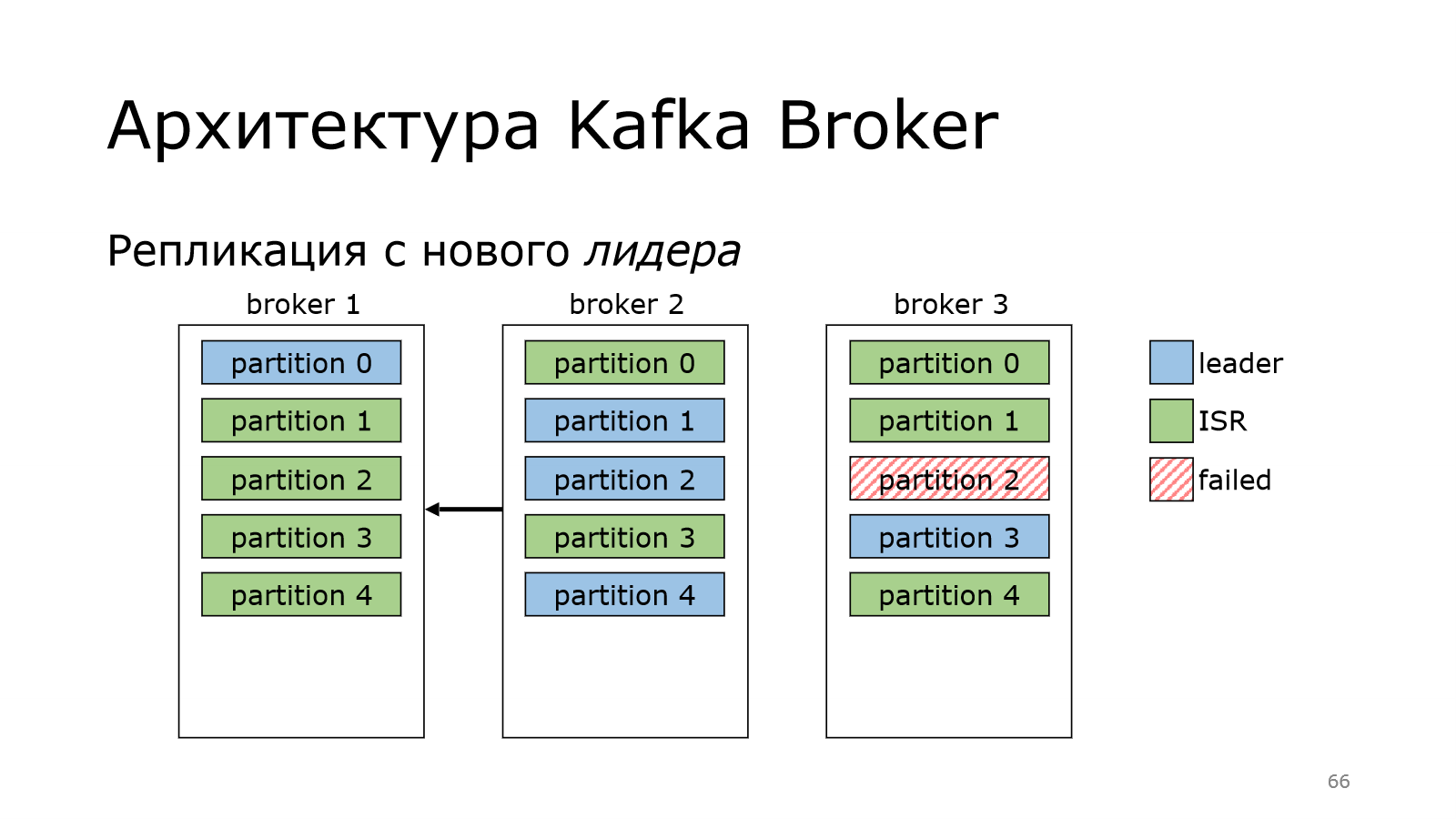
Теперь с него можно реплицировать данные по другим брокерам. Но в партиции старый лидер может ожить.

Ожил, у него все хорошо, но он успел отстать по данным, потому что лидерство сменилось, появились новые данные.
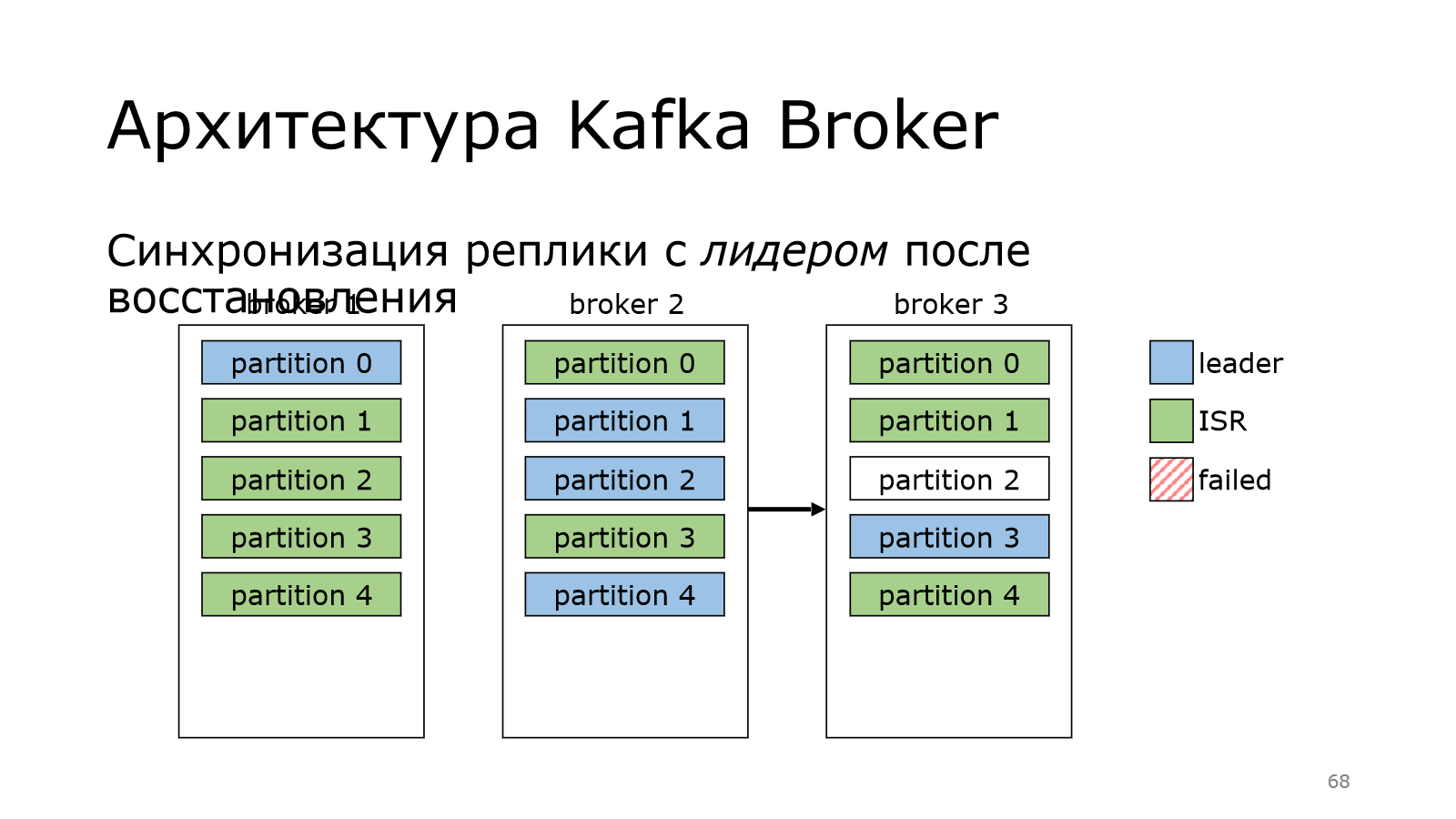
И поэтому он вынужден уже реплицироваться с нового лидера. Он это сделал. Кластер восстановился. И все хорошо.
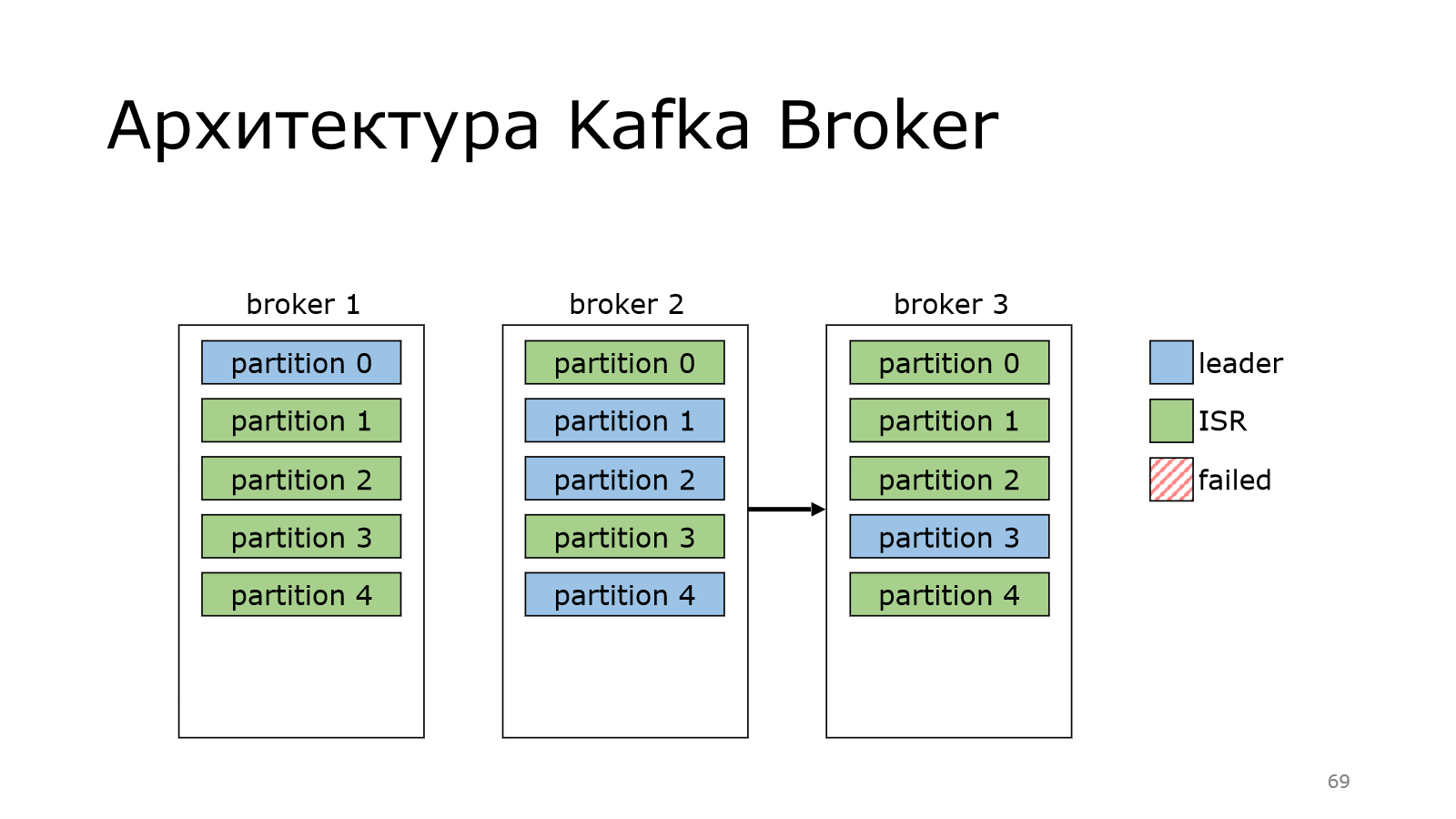
И потом в Kafka случается магия, которая – раз и возвращает лидера обратно.

Для чего это сделано? Если мы последовательно будем перезапускать ноды, мы можем взять и согнать лидерство на одного брокера. Это не очень хорошо. Он будет отвечать за всю запись, а остальные брокеры будут отдыхать. И чтобы этого не было Kafka периодически умеет это дело перебалансировать. И у нее есть куча настроек, которые это дело регламентируют.
**Архитектура Kafka Producer**

Теперь пойдем к продюсеру, т. е. поговорим о том, как данные пишутся.
Начнем с сообщения. Сообщение можно представлять, что это пара ключ, значение.
При этом для Kafka и ключ, и значение – это просто массив байтов, в который можно писать все, что угодно. Продюсер должен знать, что он туда сериализует. И consumer должен знать, что он туда десериализует.

Зачем нужен ключ? Ключ используется для определения номера партиции, куда положить данные. Используется [MurmurHash](https://ru.wikipedia.org/wiki/MurmurHash2) в том случае, если ключ есть.

Если ключа нет, то используется round robin, когда продюсер перебирает партиции по кругу, т. е. дошел до конца, начинает с нулевой и т.д.
И при этом важный point: куда положить данные решает продюсер. Т. е. не брокер как-то там сам определяет и сохраняет, а именно продюсер. Продюсер должен всегда писать в лидера. Соответственно, он пишет в конкретного брокера, в конкретную партицию. Это важно.
Про ключ я уже сказал, что Kafka это интерпретирует как массив байтов и так же сохраняет в лог, как и другую метаинформацию. Другая метаинформация – это offset, timestamp и т. д.

У нас есть одна партиция. И у нее три реплики. Они синхронизированы.
Одна из них является лидером. В каждой по 9 записей.
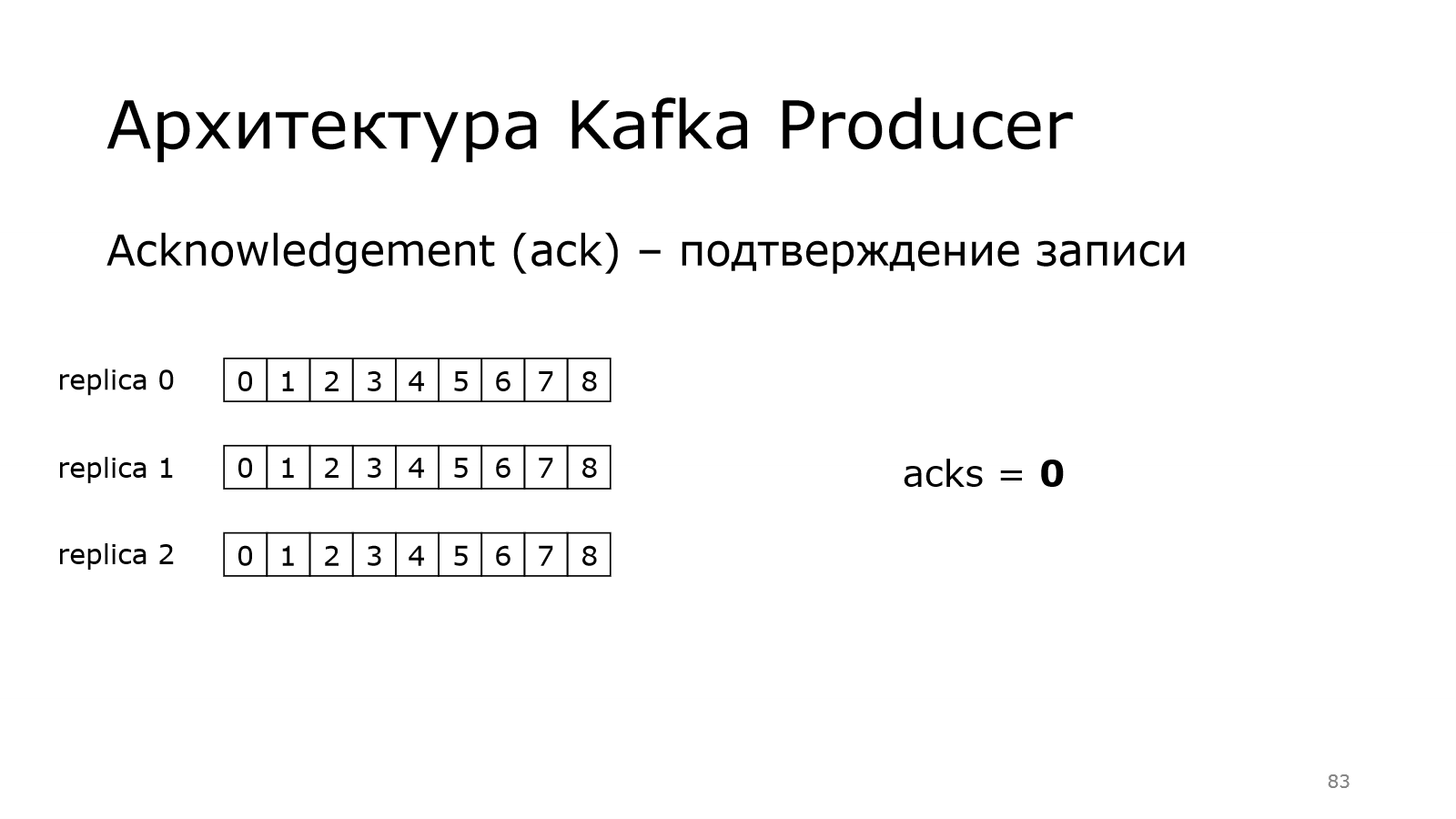
Теперь посмотрим, как работает продюсер. Есть такая штука в Kafka, как acknowledgement, т. е. подтверждение записи. Продюсер должен убедиться, что данные записались

Нулевой уровень предоставляет нулевые гарантии. Как это работает?
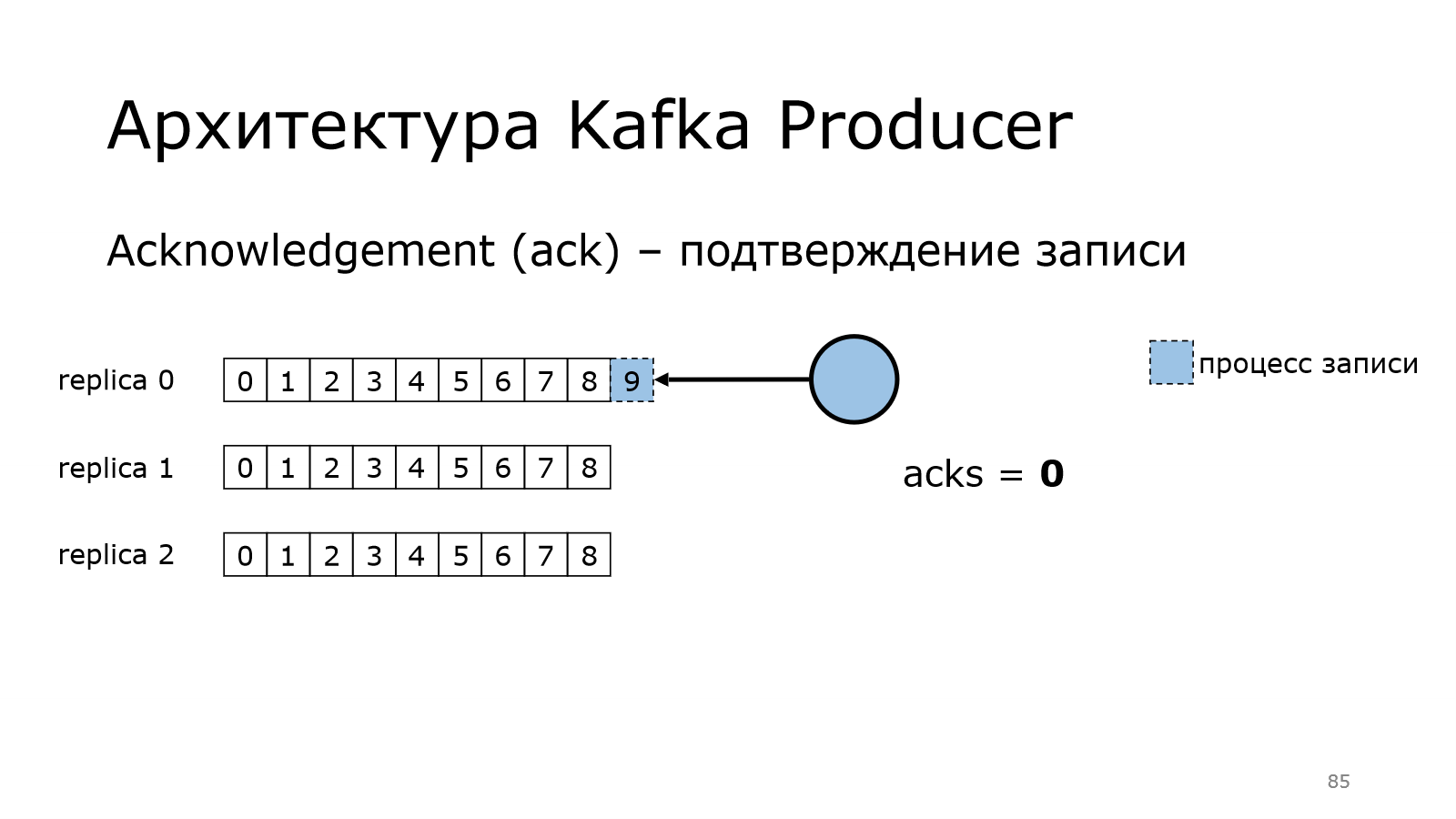
Продюсер начинает писать сообщение в одной из партиции. Он передал все данные и говорит, что у него все хорошо.

Ему не надо никакого подтверждения.
При этом данные могли записаться в Kafka, а могли не записаться. Там могла быть какая-то проблема. И лидер в реплике 0 мог не сохранить данные. И тут уже может быть потеря данных. Это нужно понимать.

Поднимаем уровень. Уровень гарантии стал 1.
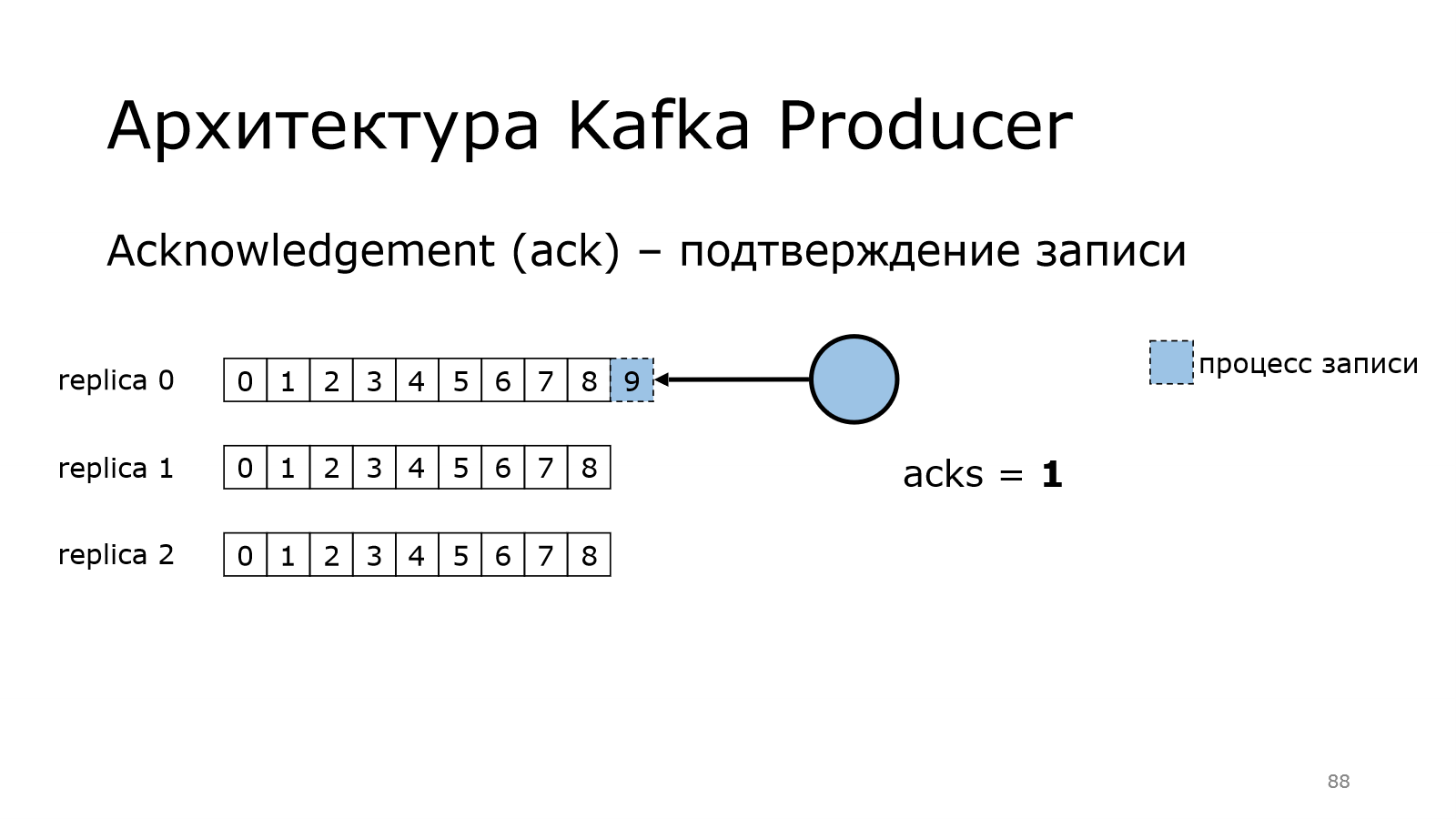
Что изменилось? Теперь продюсер пишет данные. Он передал все данные в Kafka. Kafka пишет. Он ждет.
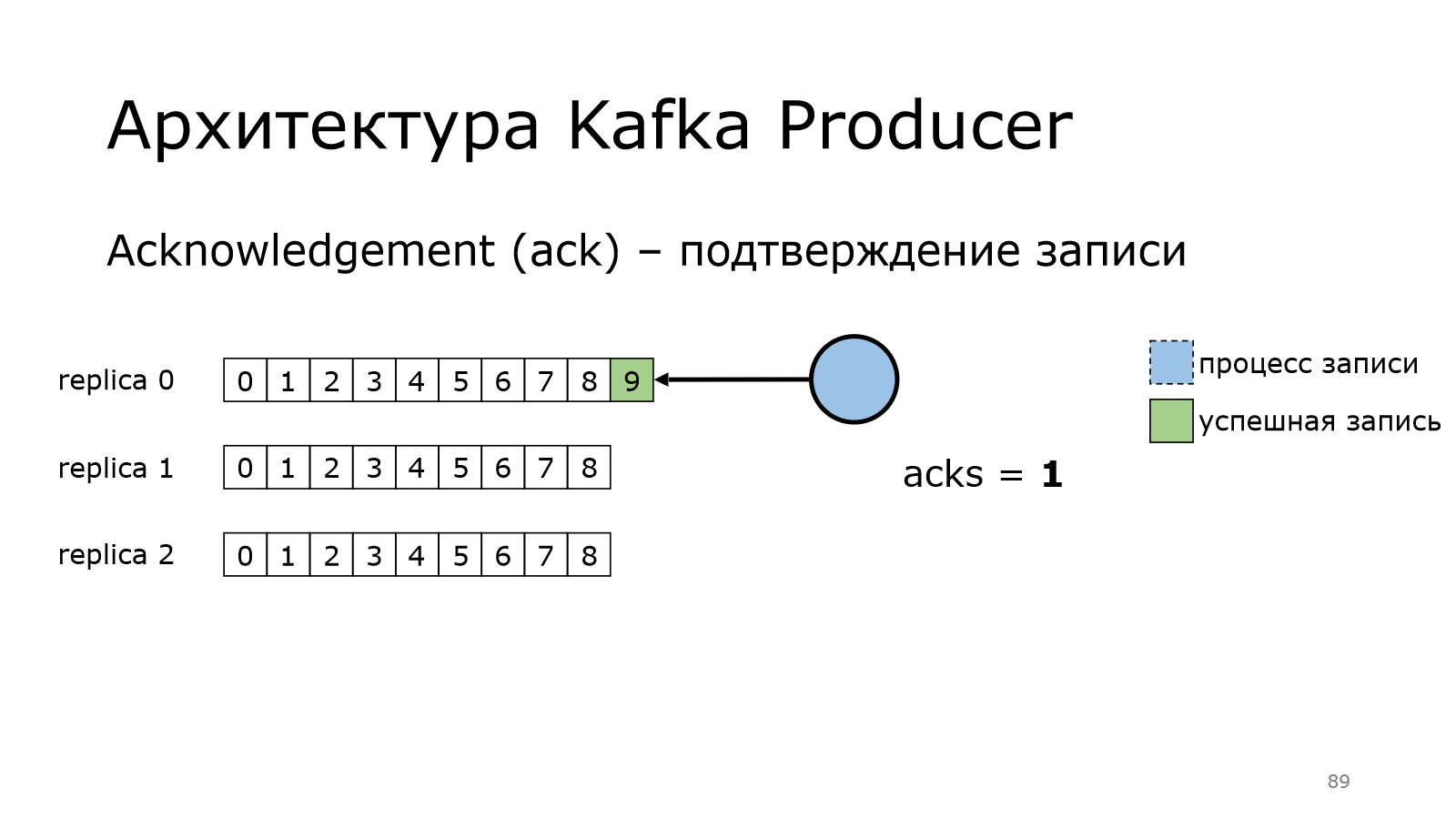
Запись произошла успешно на брокера. Брокер вернул подтверждение, что сохранил.
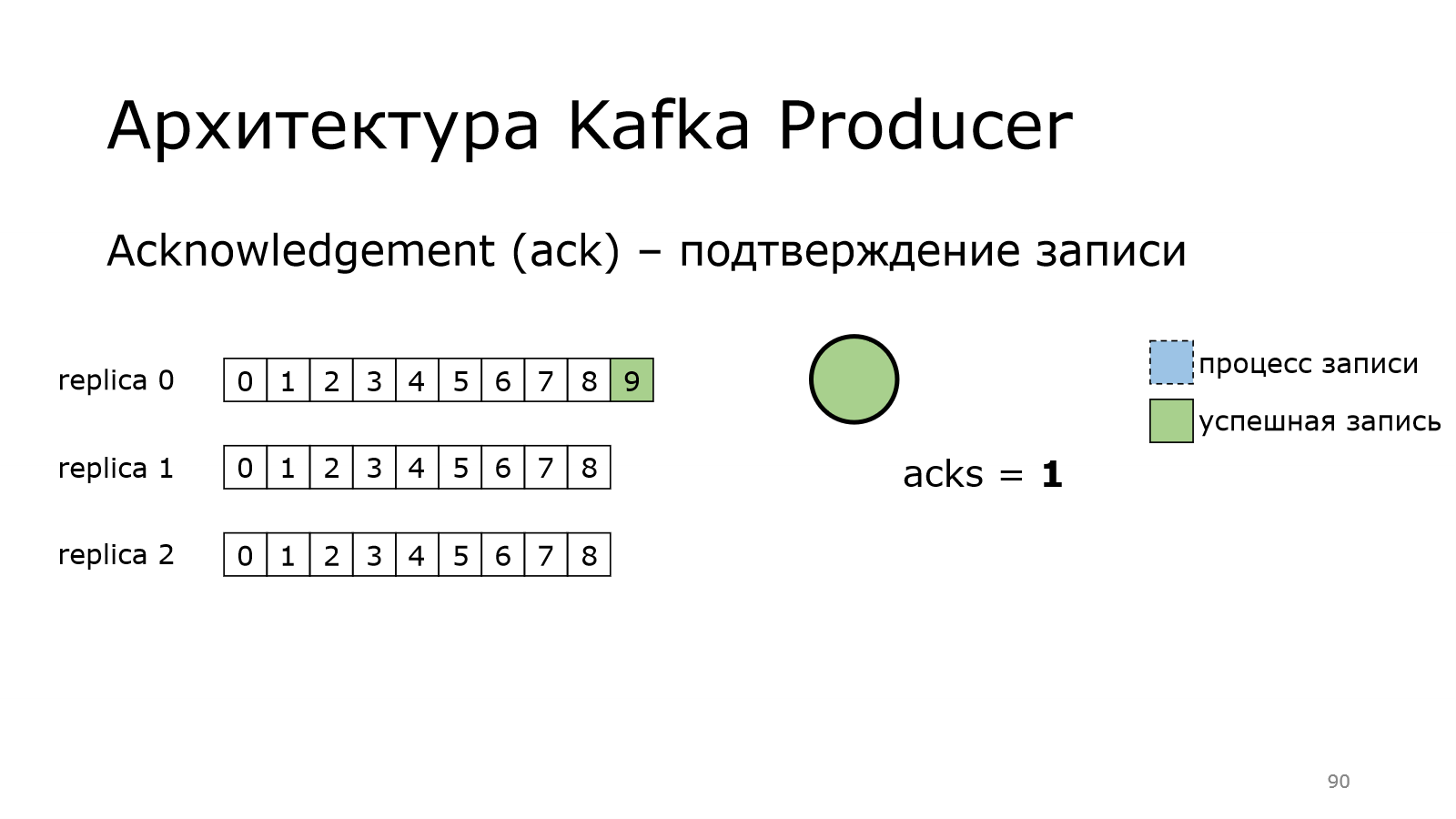
После этого продюсер считает, что все хорошо.
Какой следующий шаг?
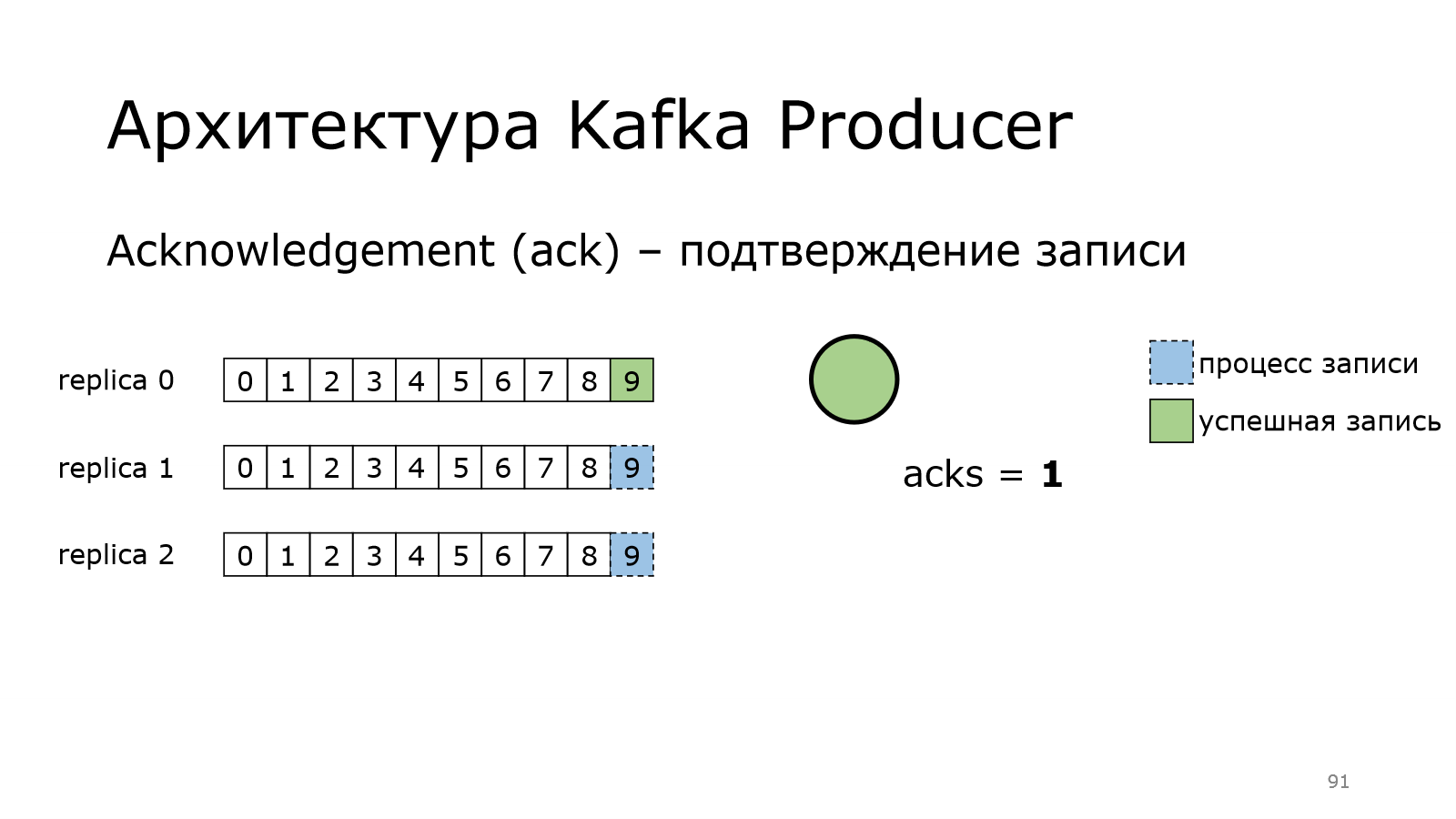
Followers приходят к лидеру и говорят: «У тебя есть новые данные?». Он говорит: «Да». И они это забирают. А могли и не забрать. Это важно. Об этом мы, может быть, позже подробней поговорим.
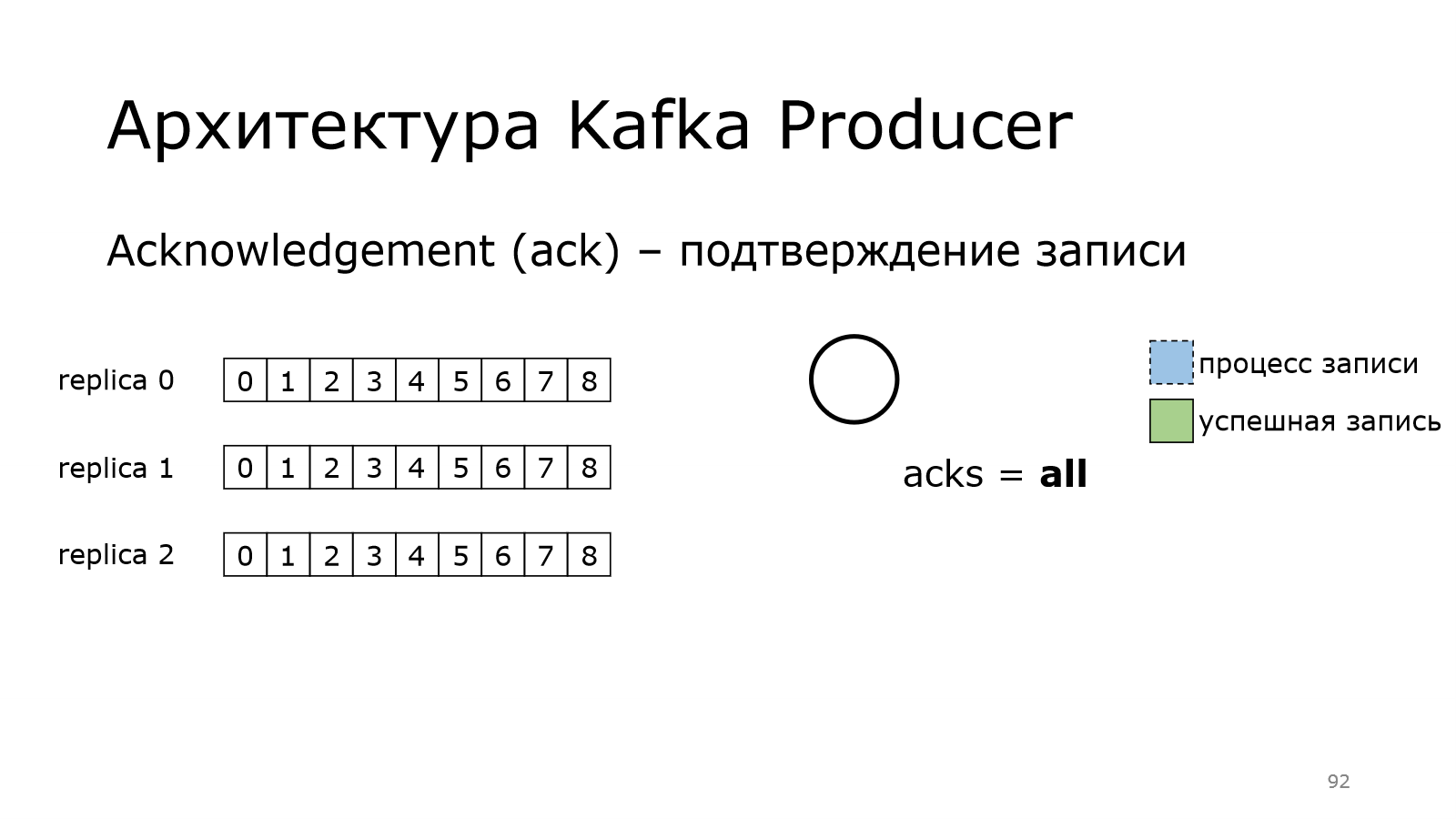
И, наконец, максимальный уровень. Уровень all, когда идем на все.

Как это работает? У нас продюсер пишет данные в лидера.
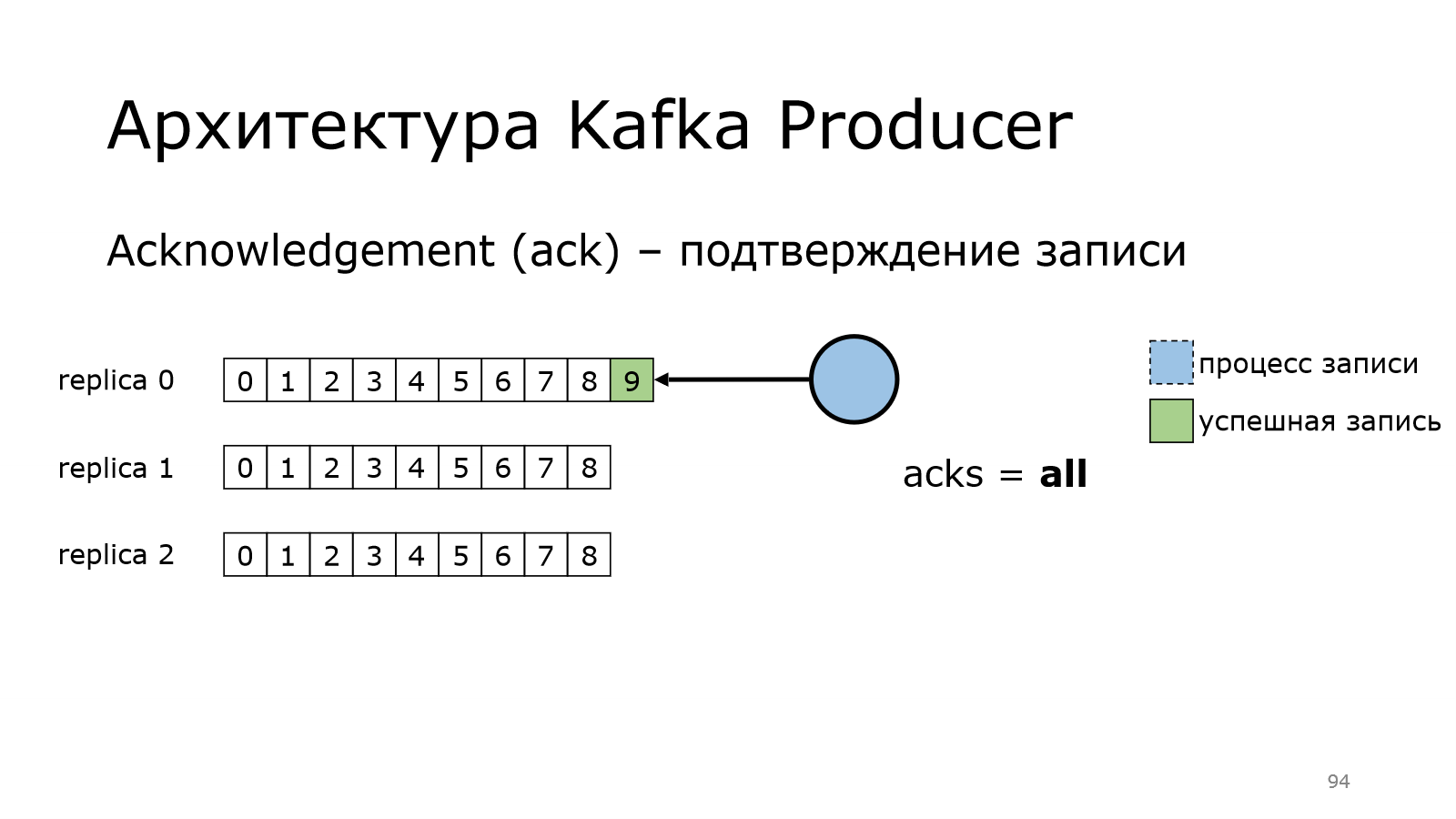
Лидер сохранил, но ничего пока не говорит продюсеру.
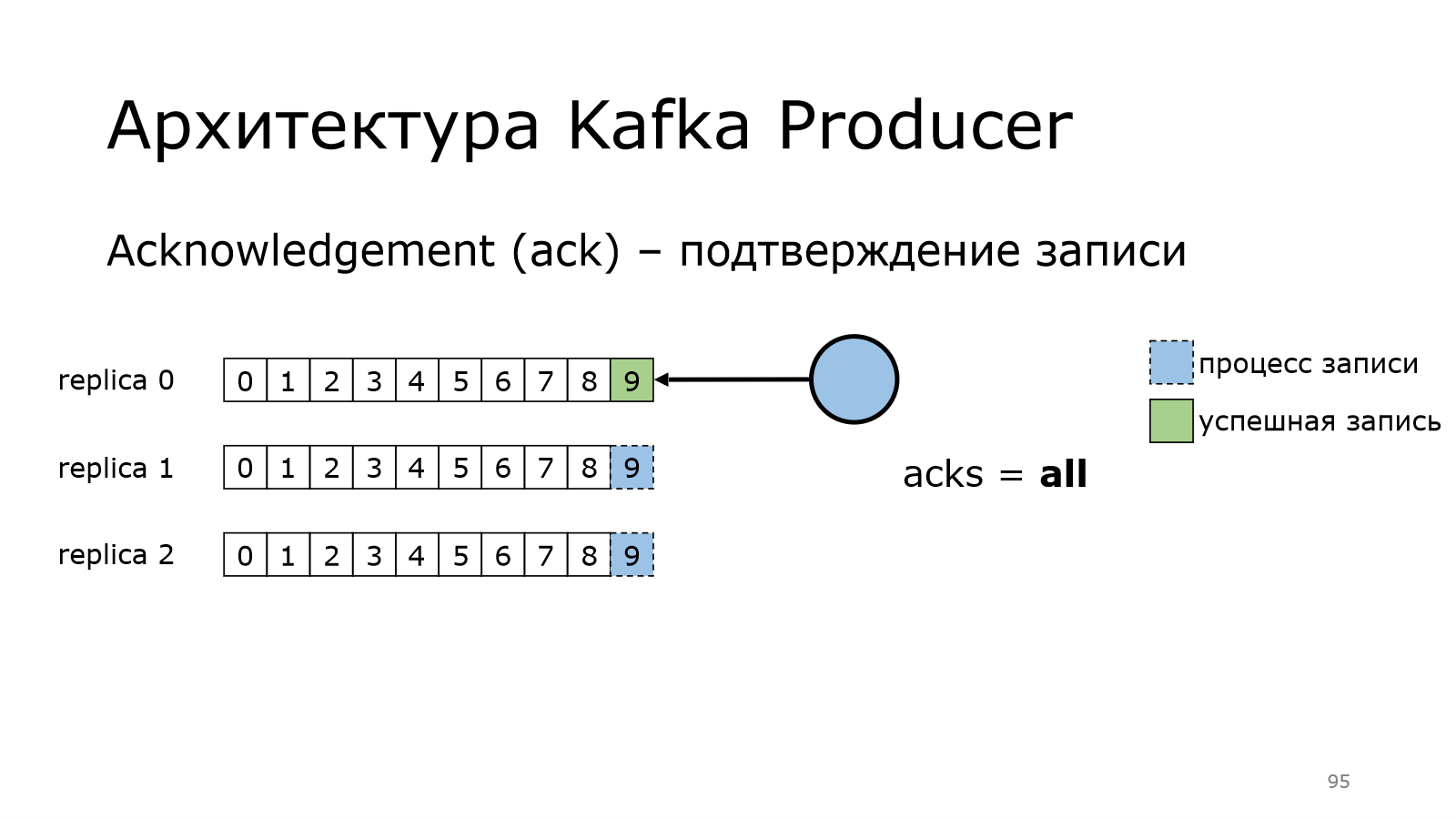
Дальше followers фоном приходят за данными.

И начинают их фетчить с лидера, пишут к себе. Записал первый, записал второй.

Брокер, который лидер, понимает, что данные записаны на всех и говорит продюсеру, что данные записались.

После этого продюсер считает, что все хорошо.
И тут появляется важная настройка появляется. Это min.insync.replicas.

Сейчас это равно 3, поэтому лидер уведомляет продюсера, что данные записались не меньше, чем в эти 3 реплики, т. е. в себе + еще 2.
Эту настройку можно понизить, тогда можно дожидаться не всех, а, допустим, `все-1`.
**Архитектура Kafka Consumer**

Теперь посмотрим, как работает consumer. У нас есть несколько партиций. Пока consumer будет читать из одной партиции. Он еще ни разу не читал, он читает с самого начала. Вот он прочитал какое-то количество сообщений.
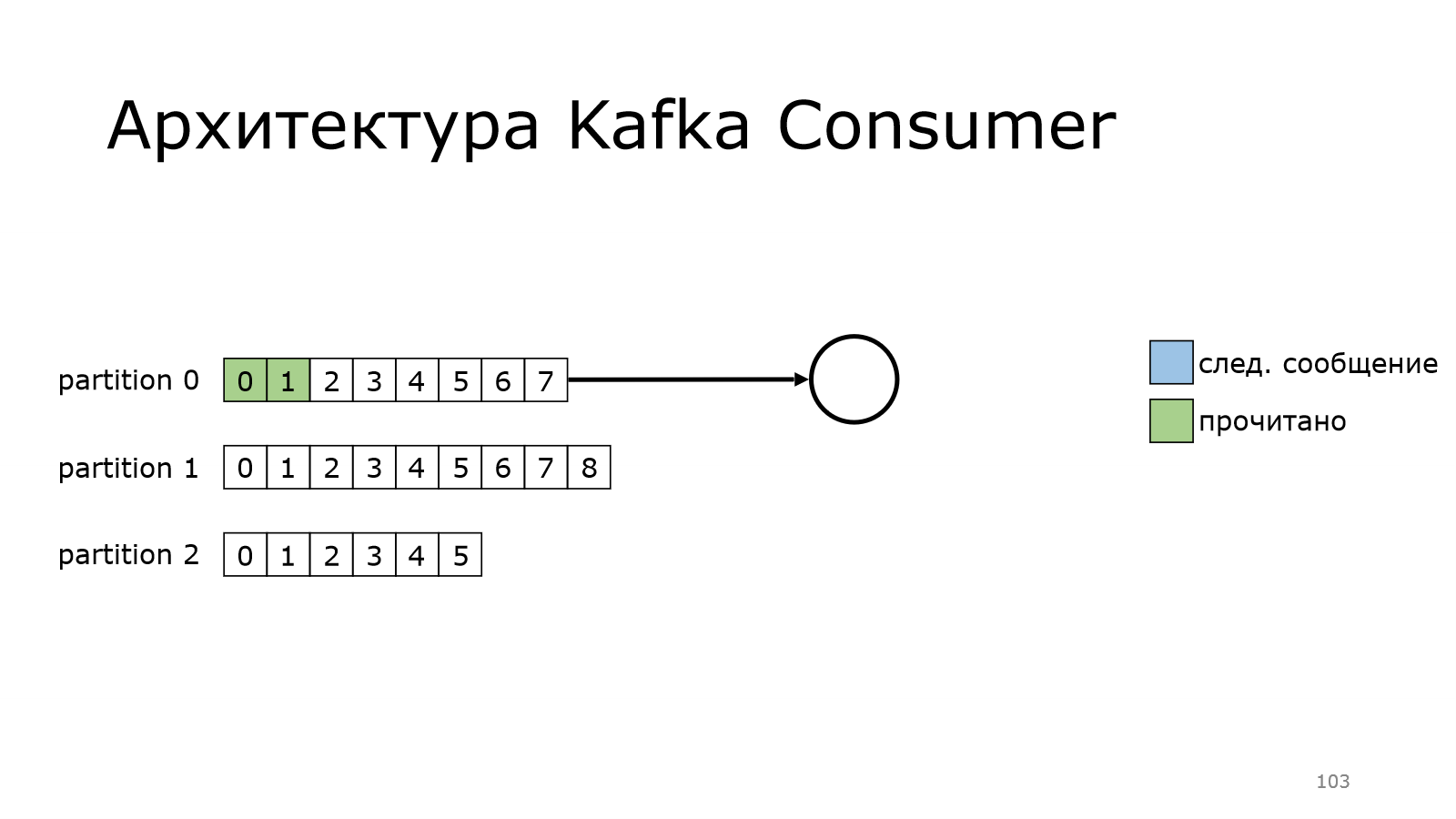
Потом перешел к следующему моменту, и так постепенно дочитывает.


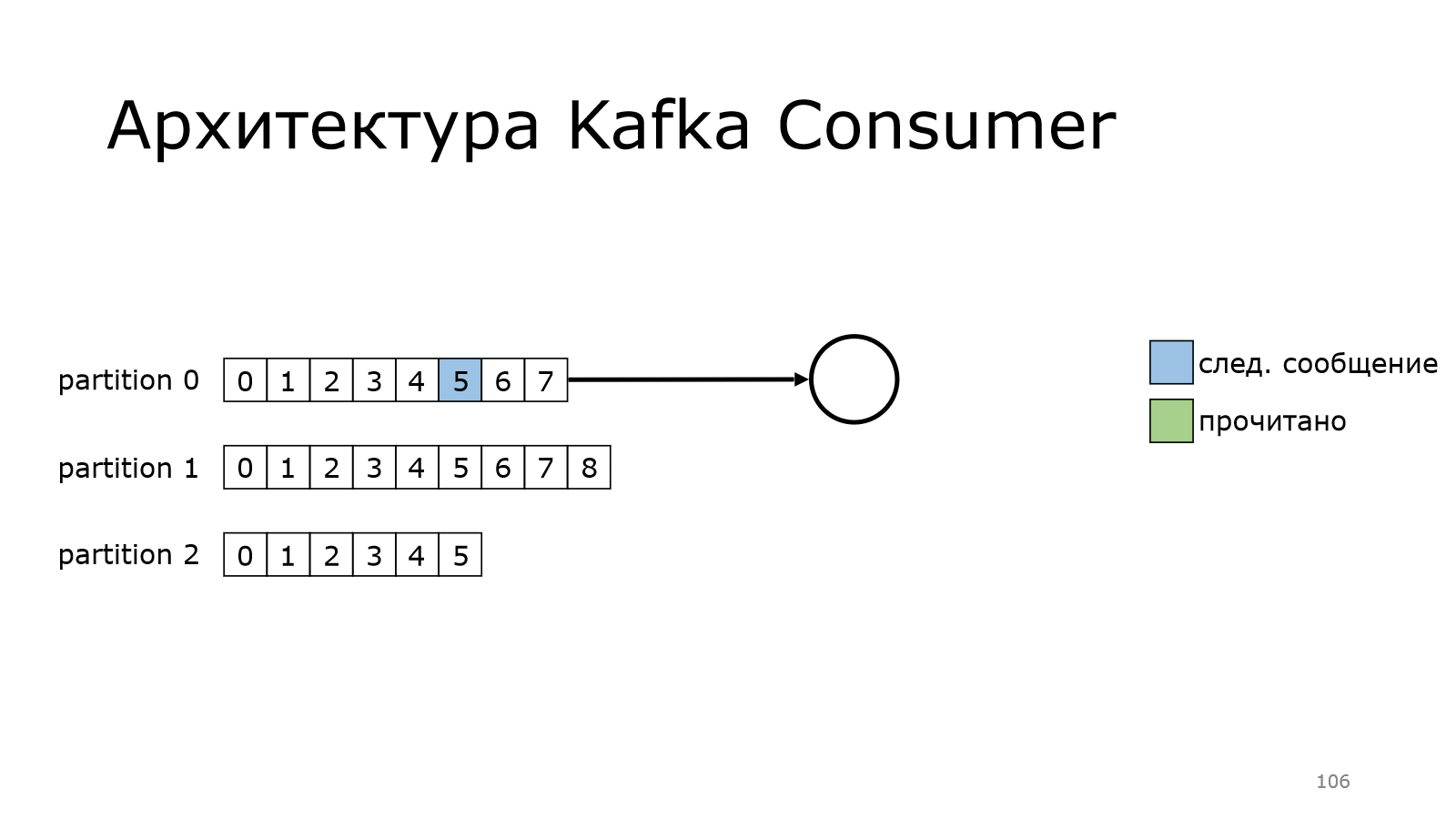
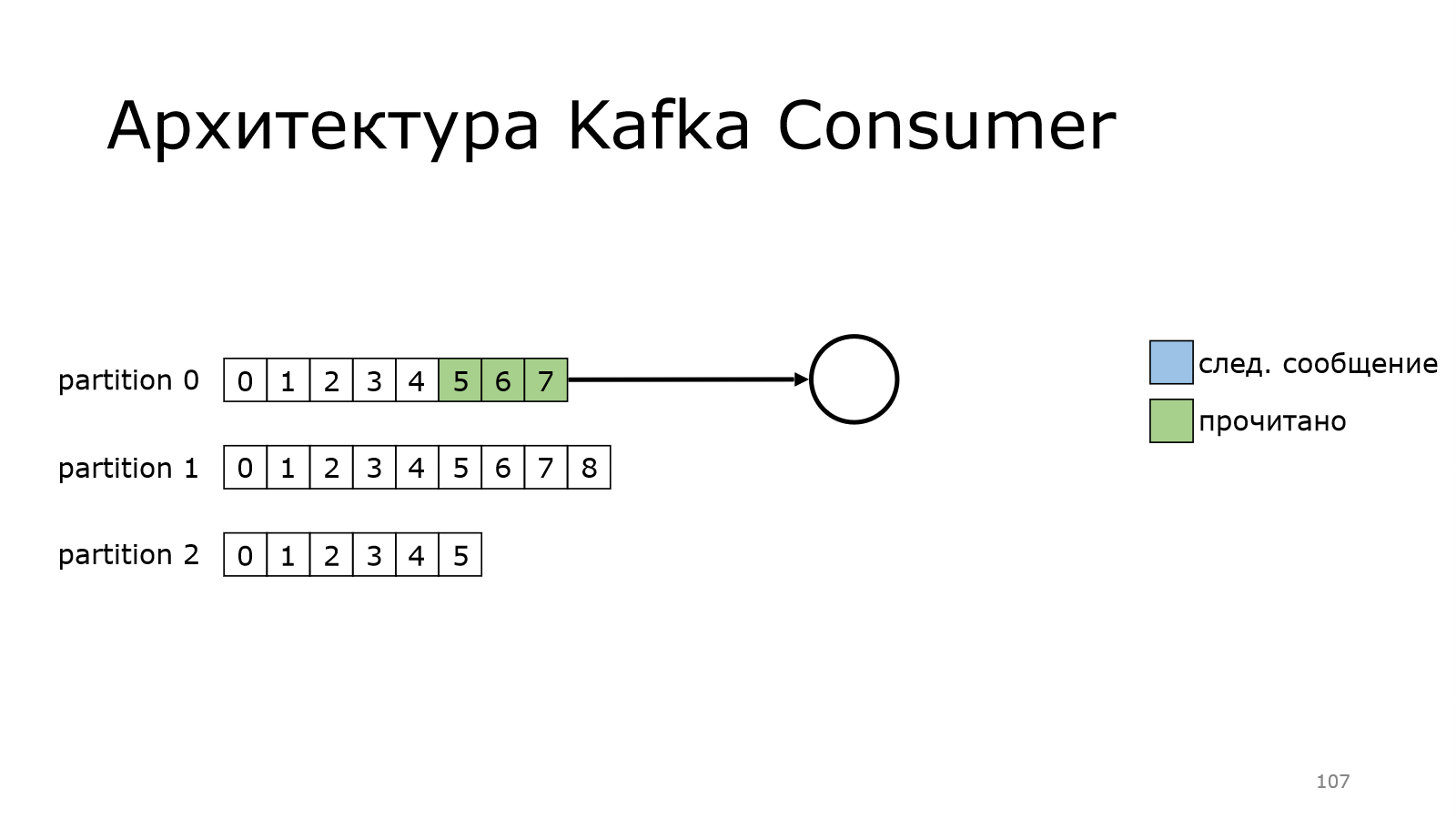
Также он может читать из нескольких партиций одновременно.

Как это выглядит?

Он на каком-то месте остановился и начинает забирать данные.
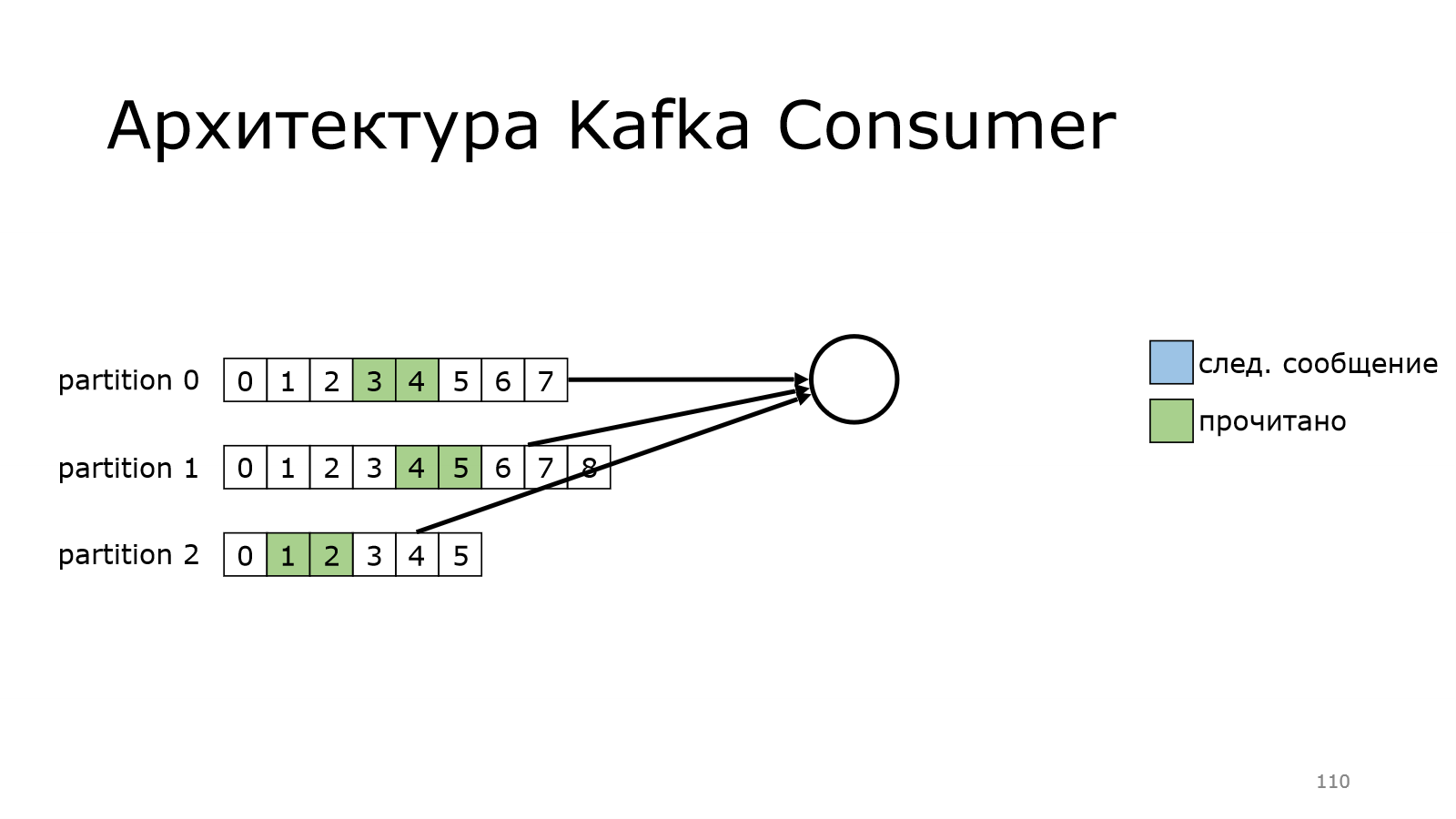
Он забрал данные.
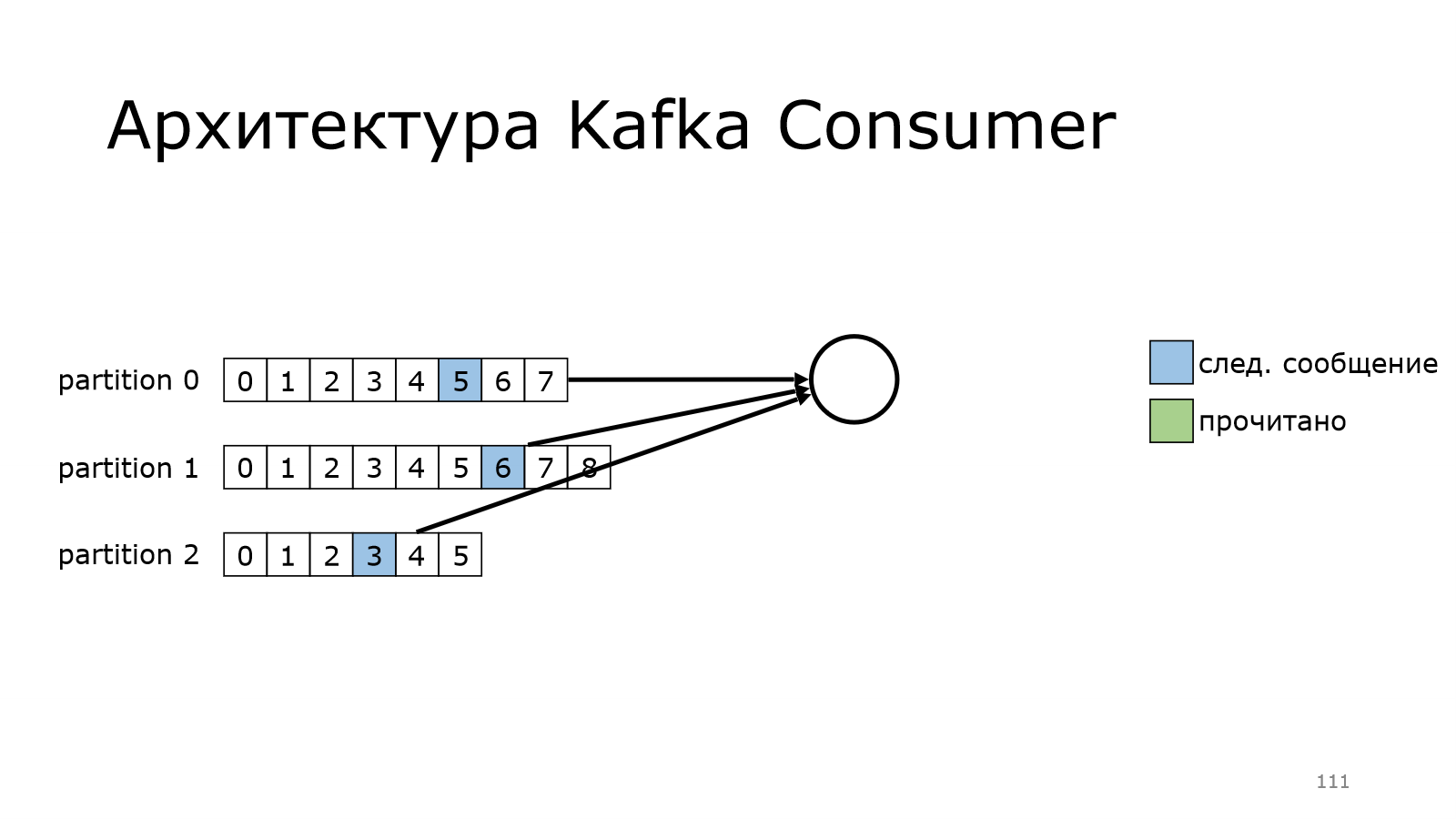
Пошел дальше-дальше и дошел до конца.
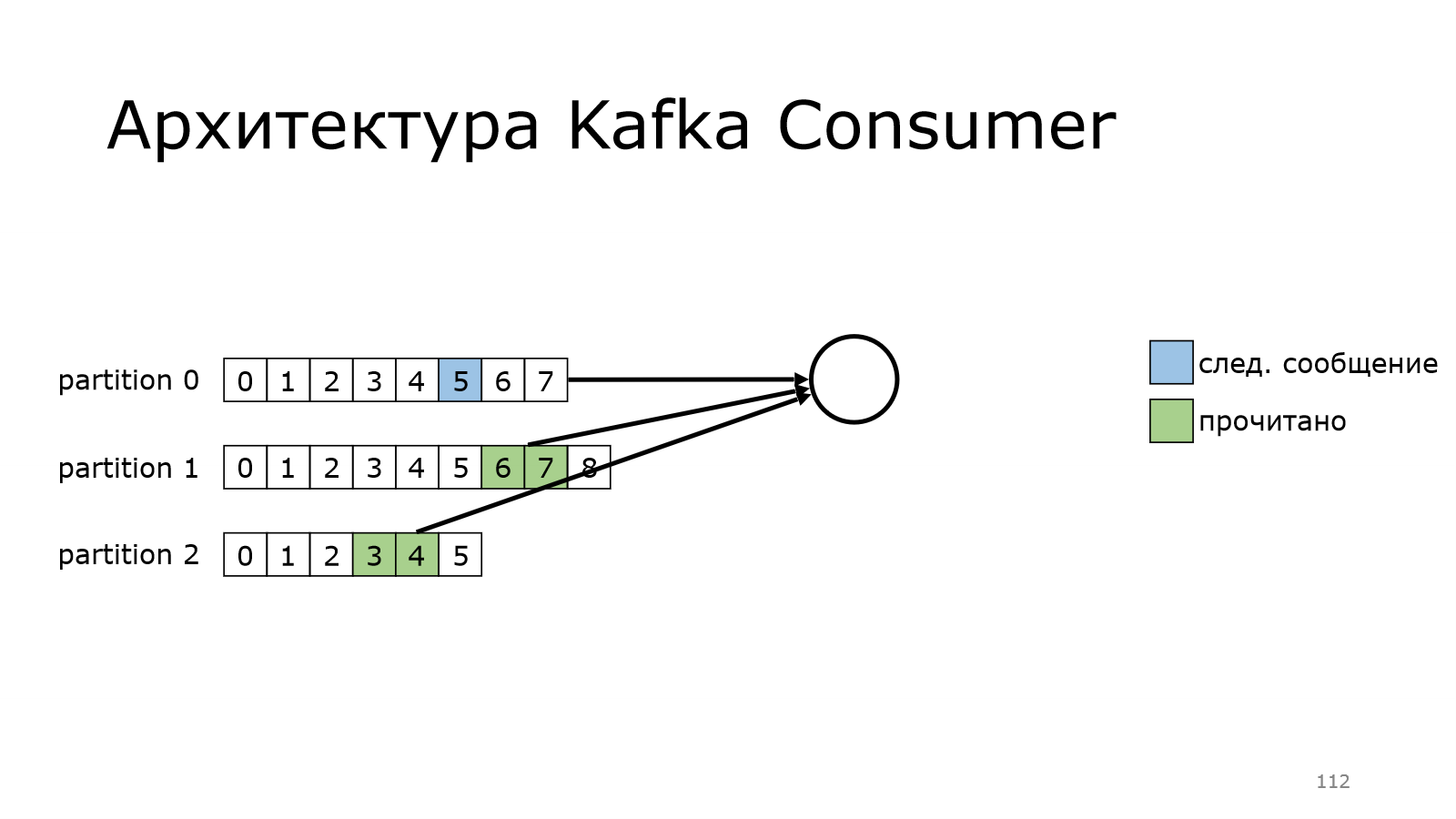
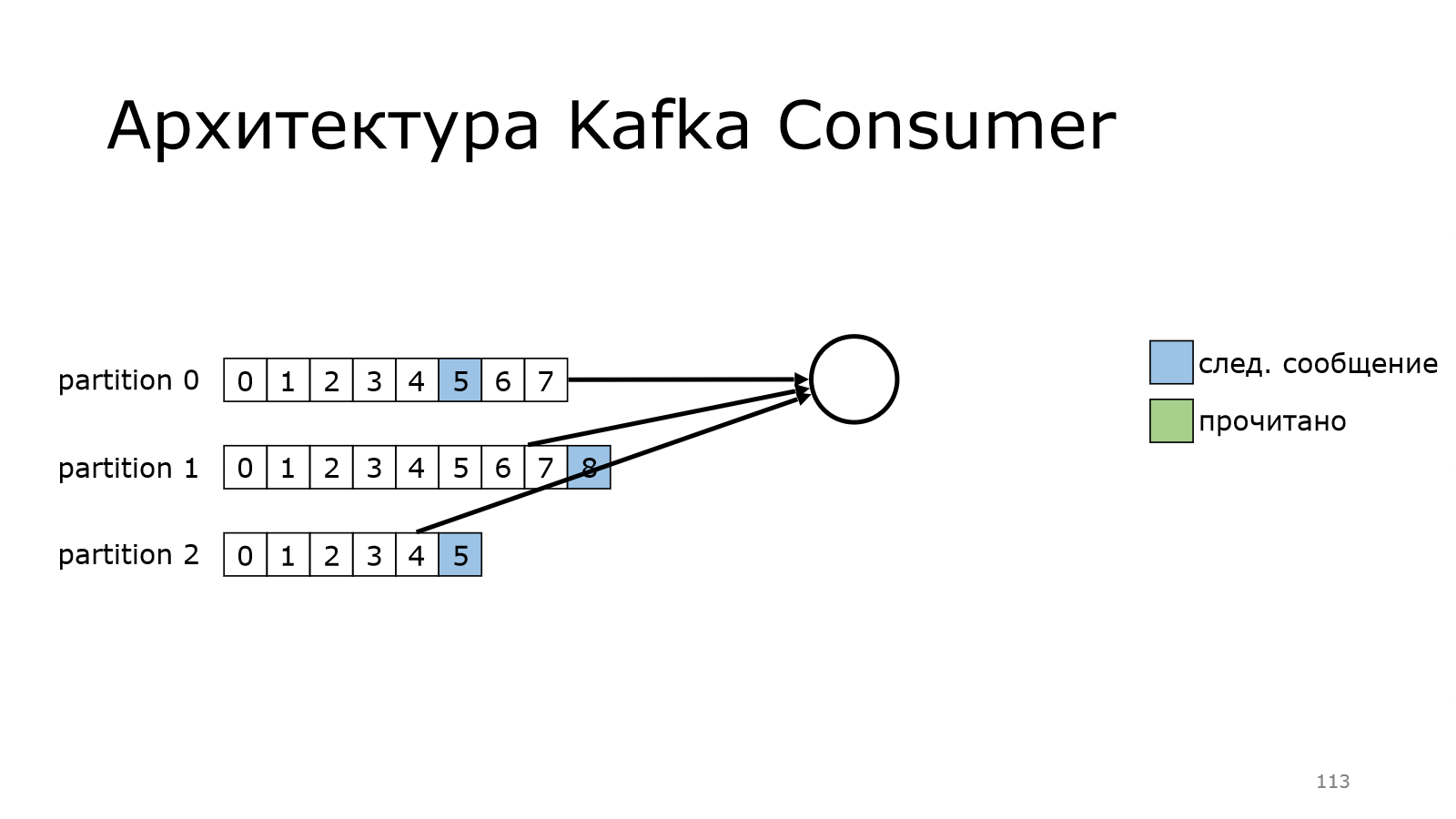
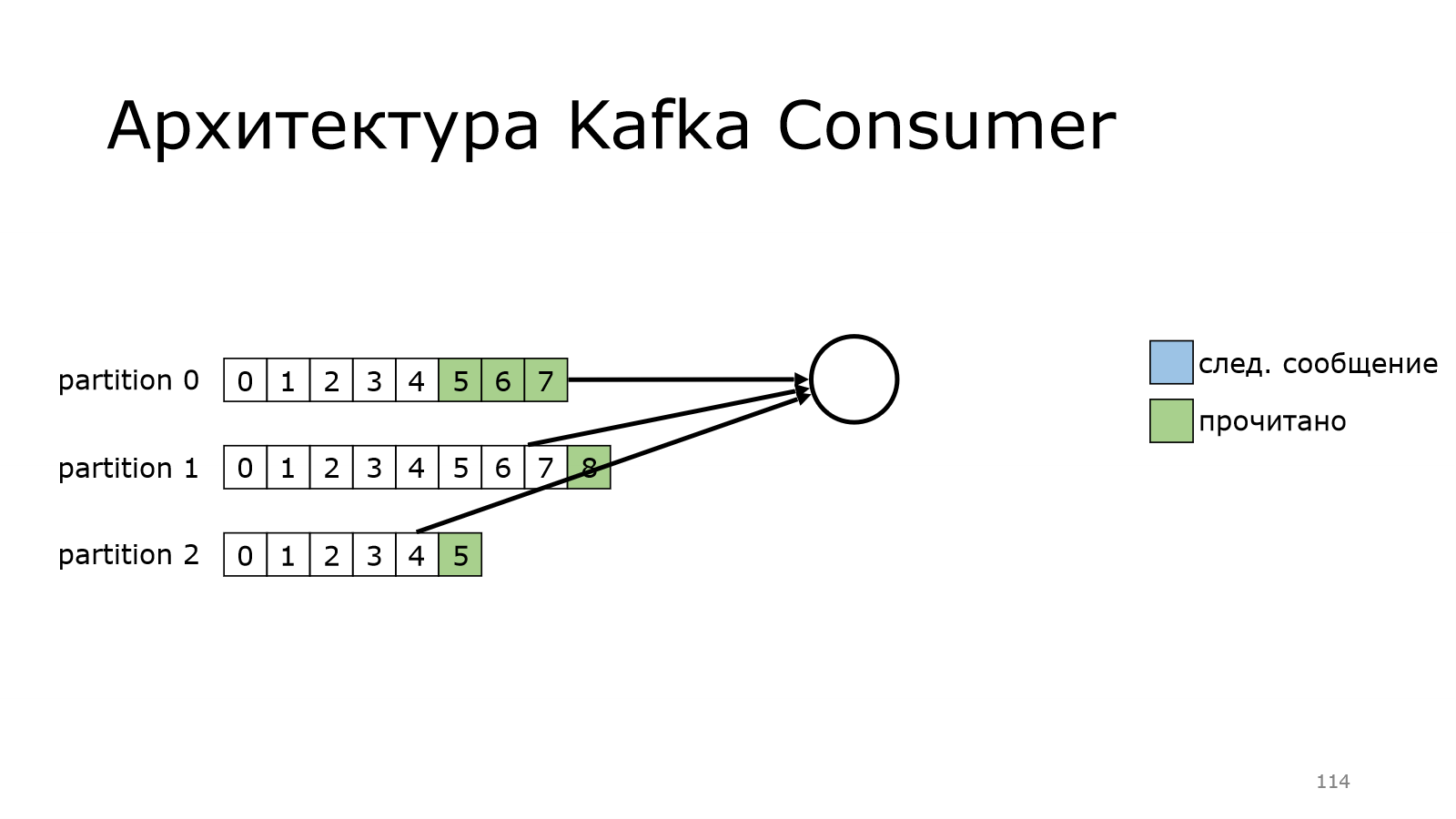

А в version polled сообщений в Kafka еще нет. И он будет продолжать делать это до тех пор, пока данные новые не появятся, и он их не получит.
Но есть маленькая тонкость. Когда вот это он делал, он запоминал место, с которого надо читать дальше. Он мог и перезапуститься, мы могли прибить процесс. И эта информация потеряется. Это понимали и те, кто делали Kafka. И поэтому добавили такую фичу, как commit offset.

Что это значит?

У нас есть consumer, он прочитал несколько сообщений.

И то значение, с которого надо начинать дальше, он коммитит. Он говорит Kafka: «Я дочитал до вот этого и с этого места я хочу потом продолжить». Соответственно, он потом продолжает и читает.

Потом у него могло произойти что-то и он отвалился.

И при этом он не успел закоммитить данные. Т. е. вот эти все сообщения считаются не закоммитченными.

И когда consumer вернется в работу, он начнет ровно с того момента, на который в последний раз закоммитил.

И с него благополучно начнет читать.

Кажется, что все логично.
Мы в какой-то момент начинаем писать много данных и нам надо уметь масштабироваться.

У нас есть consumer, который начинает уже не справляться с чтением всех данных.
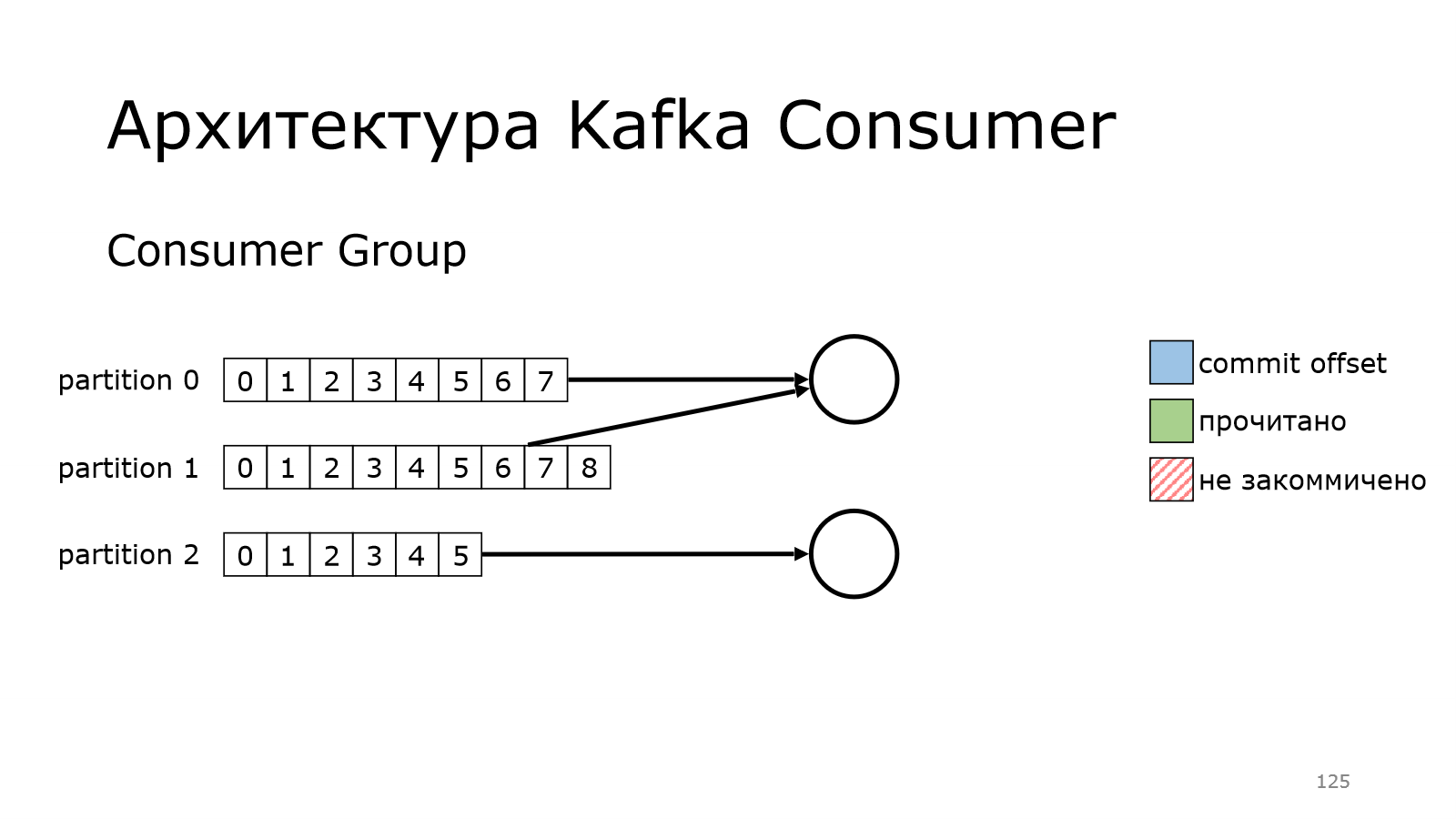
Тогда мы поднимаем еще один. И как бы мы могли это сделать? Мы могли бы сделать так, что один consumer читает из первых двух партиций, второй consumer читает из другой партиции. Но этим очень трудно управлять ручками, поэтому в Kafka предусмотрена вот такая штука.
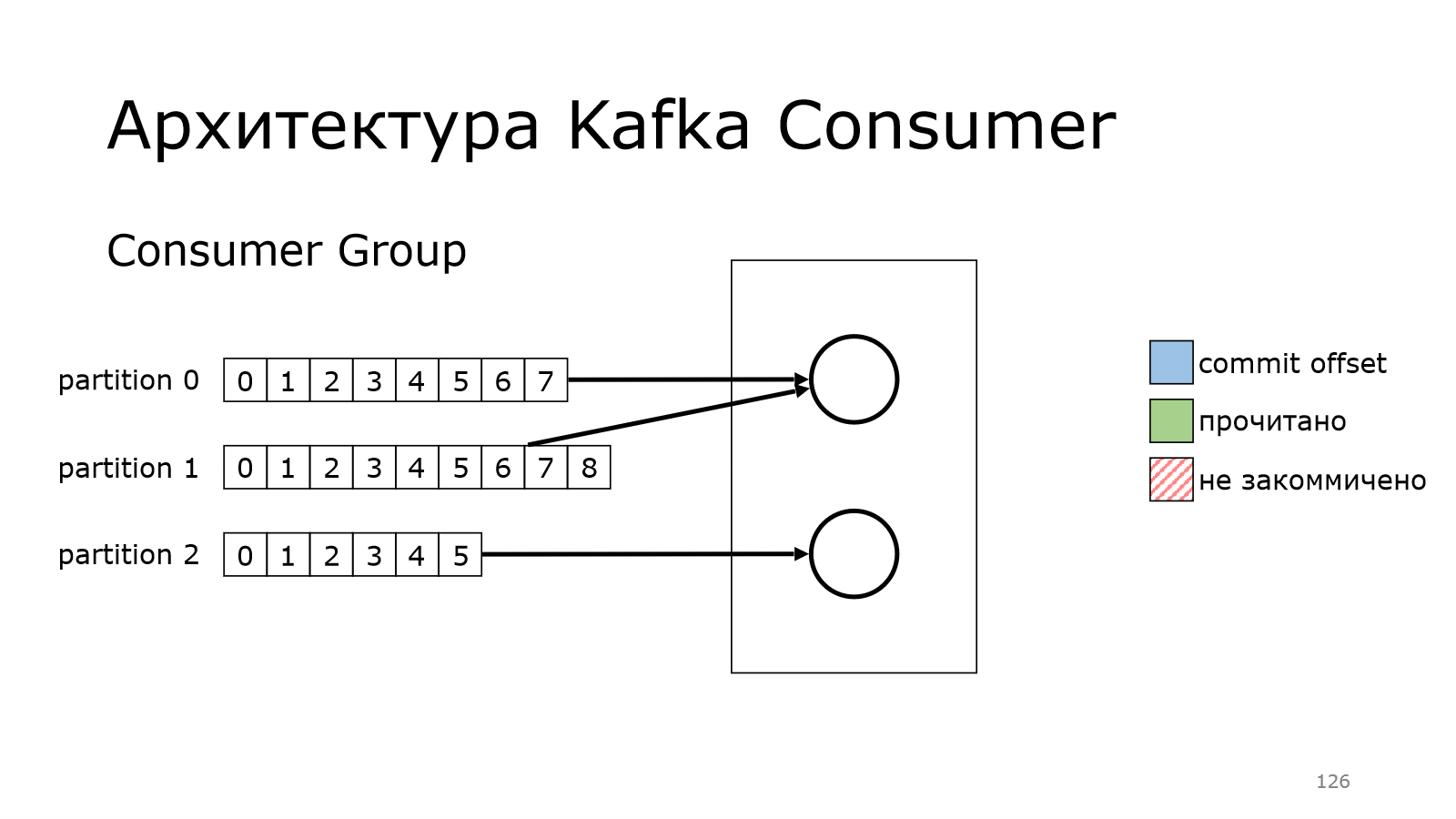
Можно взять и объединить набор consumers в группу. И у них там появляется общий идентификатор.

И когда они работают, они между ними автоматически расбалансируют все партиции и начнут читать.

У них там был какой-то offset, с которого они должны начать.

Первый почитал, второй начал читать.

И второй – бах и упал, и не докоммитил что-то.

Что произойдет? Во-первых, надо начать снова с первого сообщения.

Произойдет перебалансировка в этой группе.
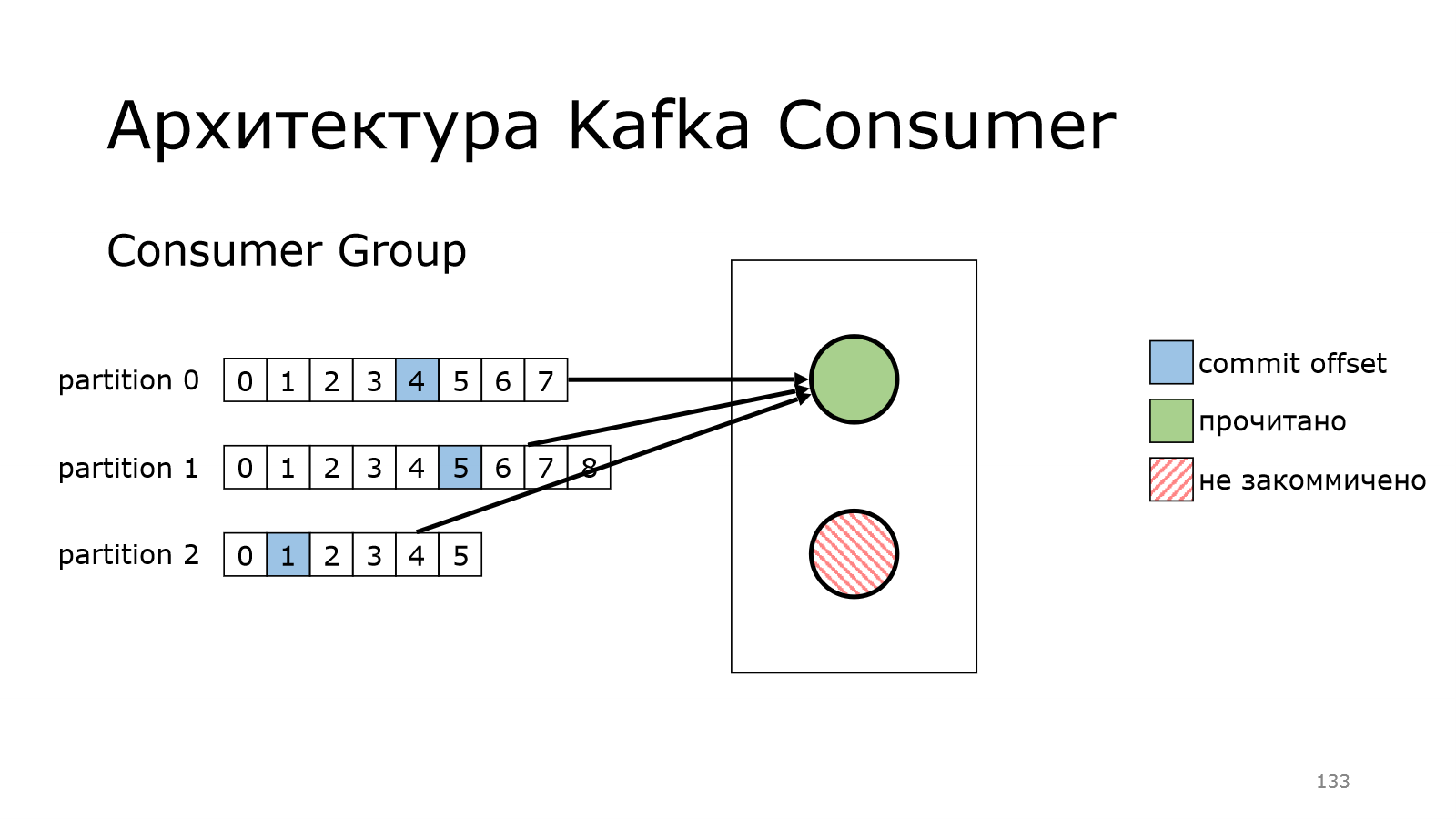
Единственный живой consumer в данном случае подхватит эту партицию.

И уже сам начнет читать данные.

И так же коммитить.

А потом consumer ожил, все у него хорошо. Он снова присоединяется к группе.

И получает какую-то партицию, с которой он может читать данные.
Кажется, что все очень просто, все хорошо работает. Там очень клевая архитектура, все очень быстро.
С Kafka всегда есть какое-нибудь «Но». Равномерное распределение партиций по количеству. Если у нас у нас в каком-то месте мало партиций, то он туда будет докидывать. Ему плевать, сколько данных у нас реально там в байтах.
И если у нас какие-то топики пишут много данных, то какие-то диски переполнились, а на каких-то может быть ничего нет. Например, раз в час какое-то сообщение падает.
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://folko.gitbook.io/podgotovka-k-sobesedovaniyu/brokery-soobshenii/kafka.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.